了解卷积层
卷积层和全连接层有什么区别?在深度神经网络中使用卷积层的背后是什么样的直觉?
我们将展示卷积层的一些效果,以提供关于卷积层做什么的一些说明。
import os
import numpy as np
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
basedir = './data/images'
def read_rgb_image(imagepath):
image = cv2.imread(imagepath) # Height, Width, Channel
(major, minor, _) = cv2.__version__.split(".")
if major == '3':
# version 3 is used, need to convert
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
else:
# Version 2 is used, not necessary to convert
pass
return image
def read_gray_image(imagepath):
image = cv2.imread(imagepath) # Height, Width, Channel
(major, minor, _) = cv2.__version__.split(".")
if major == '3':
# version 3 is used, need to convert
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
else:
# Version 2 is used, not necessary to convert
image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
return image
def plot_channels(array, filepath='out.jpg'):
"""Plot each channel component separately
Args:
array (numpy.ndarray): 3-D array (width, height, channel)
"""
ch_number = array.shape[2]
fig, axes = plt.subplots(1, ch_number)
for i in range(ch_number):
# Save each image
# cv2.imwrite(os.path.join(basedir, 'output_conv1_{}.jpg'.format(i)), array[:, :, i])
axes[i].set_title('Channel {}'.format(i))
axes[i].axis('off')
axes[i].imshow(array[:, :, i], cmap='gray')
plt.savefig(filepath)
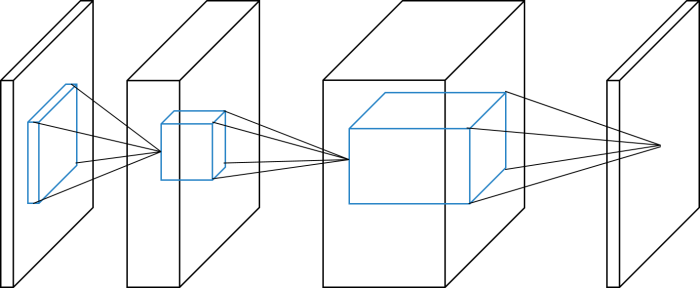
以上类型的图经常出现在卷积神经网络领域。下图解释了它的符号。
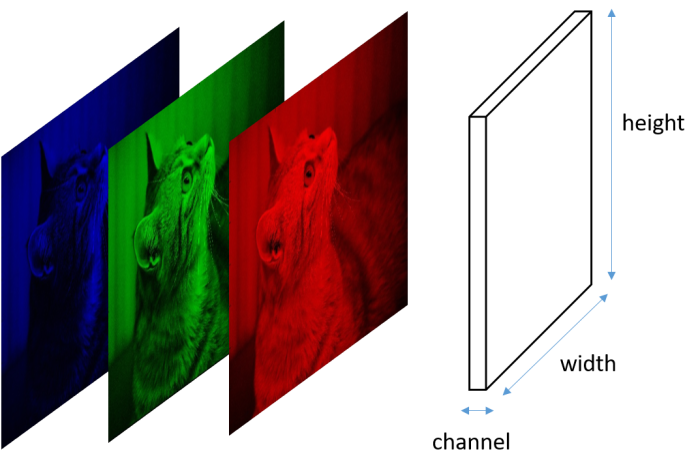
立方体表示“图像”数组,其中此图像可能不意味着有意义的图像。水平轴分别代表通道号,图像高度垂直轴和图像宽度深度轴。
卷积层 - 基本用法
卷积层的输入格式是按顺序(批量索引,通道,高度,宽度)。由于openCV图像格式的顺序是(高度,宽度,通道),所以这个维度顺序需要转换为卷积层的输入。这可以通过使用转置方法来完成。
L.Convolution2D(in_channels, out_channels, ksize)
in_channels: 输入图像通道数
out_channels: 输出通道数
ksize: 卷积核大小
同样,还剩下可以设定的参数有
pad: 填充
stride: 步长
import chainer.links as L
# Read image from file, save image with matplotlib using `imshow` function
imagepath = os.path.join(basedir, 'sample.jpeg')
image = read_rgb_image(imagepath)
# height and width shows pixel size of this image
# Channel=3 indicates the RGB channel
print('image.shape (Height, Width, Channel) = ', image.shape)
image.shape (Height, Width, Channel) = (360, 640, 3)
conv1 = L.Convolution2D(None, 3, 5)
# Need to input image of the form (batch index, channel, height, width)
image = image.transpose(2, 0, 1)
image = image[np.newaxis, :, :, :]
# Convert from int to float
image = image.astype(np.float32)
print('image shape', image.shape)
image shape (1, 3, 360, 640)
# Convert from int to float
image = image.astype(np.float32)
print('image shape', image.shape)
out_image = conv1(image).data
print('shape', out_image.shape)
image shape (1, 3, 360, 640)
shape (1, 3, 356, 636)
out_image = out_image[0].transpose(1, 2, 0)
print('shape 2', out_image.shape)
plot_channels(out_image,
filepath=os.path.join(basedir, 'output_conv1.jpg'))
shape 2 (356, 636, 3)

Convolution2D 将4维数组作为输入并输出4维数组。该输入输出关系的图形意义如下图所示。

当in_channels设置为None时,其大小在使用时第一次确定。即上述代码中的out_image = conv1(image).data。内部参数W在此时被随机初始化。正如你所看到的,output_conv1.jpg显示了应用随机过滤器后的结果。一些“特征”可以通过应用卷积层来提取。例如,随机滤波器有时用作“模糊”或“边缘提取”图像。要更详细地理解卷积层的直观含义,请参见下面的示例。
gray_image = read_gray_image(imagepath)
print('gray_image.shape (Height, Width) = ', gray_image.shape)
# Need to input image of the form (batch index, channel, height, width)
gray_image = gray_image[np.newaxis, np.newaxis, :, :]
# Convert from int to float
gray_image = gray_image.astype(np.float32)
gray_image.shape (Height, Width) = (360, 640)
conv_vertical = L.Convolution2D(1, 1, 3)
conv_horizontal = L.Convolution2D(1, 1, 3)
print(conv_vertical.W.data)
[[[[ 0.07080602 0.2954087 -0.04944068]
[-0.35561612 0.37188312 0.27154291]
[-0.00589179 0.10385436 0.43923417]]]]
conv_vertical.W.data = np.asarray([[[[-1., 0, 1], [-1, 0, 1], [-1, 0, 1]]]])
conv_horizontal.W.data = np.asarray([[[[-1., -1, -1], [0, 0., 0], [1, 1, 1]]]])
print('image.shape', image.shape)
out_image_v = conv_vertical(gray_image).data
out_image_h = conv_horizontal(gray_image).data
print('out_image_v.shape', out_image_v.shape)
out_image_v = out_image_v[0].transpose(1, 2, 0)
out_image_h = out_image_h[0].transpose(1, 2, 0)
print('out_image_v.shape (after transpose)', out_image_v.shape)
image.shape (1, 3, 360, 640)
out_image_v.shape (1, 1, 358, 638)
out_image_v.shape (after transpose) (358, 638, 1)
plt.imshow(out_image_v[:, :, 0],cmap="gray")
<matplotlib.image.AxesImage at 0x14d771160>

plt.imshow(out_image_h[:, :, 0],cmap="gray")
<matplotlib.image.AxesImage at 0x14f517d30>

从结果中可以看出,每个卷积层都可以沿着特定的方向强调/提取色差。这样的“过滤器”,也被称为“内核”可以被认为是特征提取器。
带有步幅的卷积
步幅的默认值是1。如果指定了这个值,卷积层将减小输出图像的大小。实际上,stride = 2通常用于生成几乎是输入图像一半的高度和宽度的输出图像。
print('image.shape (Height, Width, Channel) = ', image.shape)
conv2 = L.Convolution2D(None, 5, 3, 2)
print('input image.shape', image.shape)
out_image = conv2(conv1(image)).data
print('out_image.shape', out_image.shape)
out_image = out_image[0].transpose(1, 2, 0)
plot_channels(out_image,
filepath=os.path.join(basedir, 'output_conv2.jpg'))
image.shape (Height, Width, Channel) = (1, 3, 360, 640)
input image.shape (1, 3, 360, 640)
out_image.shape (1, 5, 177, 317)

这是ConvNets中二维卷积的一个实现。它需要三个变量:输入图像$ x $,过滤器权重$ W $和偏向量$ b $。
这里是维度的符号的一些定义。
$n$是批量大小。 $c_I$和$c_O$ 分别是输入和输出通道的数量。 $h_I$和$w_I$ 分别是输入图像的高度和宽度。 $h_K$和$w_K$ 分别是过滤器的高度和宽度。 $h_P$和$w_P$ 分别是空间填充大小的高度和宽度。
然后,Convolution2D函数计算和x中滤波器和($h_K$,$w_K$)大小的图像块之间的相关性。
请注意,这里的相关性相当于扩展向量之间的内积。对于每个空间轴,在从第一位置($-h_P$,$-w_P$)移位多个步幅的位置处提取图像块。最右侧(或最底部)的图像块不会超过填充的空间大小。
令($s_Y$,$s_X$)是过滤器步幅的大小。那么,输出尺寸($h_O$,$w_O$)由以下等式确定:
$h_O,w_O=(h_I+2h_P−h_K)/s_Y+1,(w_I+2_wP−w_K)/s_X+1$.
如果cover_all选项为True,则过滤器将覆盖所有空间位置。因此,如果最后一步的过滤器不覆盖空间位置的末端,则将在空间位置的末端部分应用附加步幅。在这种情况下,输出大小($h_O$,$w_O$) 由以下等式确定:
$h_O,w_O=(h_I+2h_P−h_K+s_Y−1)/s_Y+1,(w_I+2w_P−w_K+s_X−1)/s_X+1$.
如果给定偏置向量,则将其添加到卷积输出的所有空间位置。
当使用cuDNN时,这个函数的输出可能是不确定的。如果chainer.configuration.config.cudnn_deterministic为True且cuDNN版本> = v3,则强制cuDNN使用确定性算法。
卷积连接可以使用称为自动调整的cuDNN特征,为固定尺寸的图像选择最有效的CNN算法,可以为固定的神经网络提供显着的性能提升。要启用,请设置chainer.using_config('autotune',True)
当dilation大于1时,除非CuDNN版本为6.0或更高版本,否则不使用cuDNN
最大池化
带有步幅的卷积层可以用来查看大范围的特征,另一种流行的方法是使用最大池化。最大池功能提取当前核对应输入的最大值,并将其余像素的信息丢弃. 这种行为有利于强加平移对称性。例如,考虑狗的照片。即使每个像素移动一个像素,仍然应该被识别为狗。因此,可以利用对称性来减少模型的计算时间和图像分类任务的内部参数个数。
from chainer import functions as F
print('image.shape (Height, Width, Channel) = ', image.shape)
print('input image.shape', image.shape)
out_image = F.max_pooling_2d(image, 2).data
print('out_image.shape', out_image.shape)
out_image = out_image[0].transpose(1, 2, 0)
plot_channels(out_image,
filepath=os.path.join(basedir, 'output_max_pooling.jpg'))
image.shape (Height, Width, Channel) = (1, 3, 360, 640)
input image.shape (1, 3, 360, 640)
out_image.shape (1, 3, 180, 320)

卷积神经网络
通过将上述功能与非线性激活单元结合,可以构建卷积神经网络(CNN)。对于非线性激活,经常使用relu,leaky_relu,sigmoid或tanh。
import chainer
class SimpleCNN(chainer.Chain):
def __init__(self):
super().__init__(
conv1=L.Convolution2D(None, 5, 3),
conv2=L.Convolution2D(None, 5, 3),
)
def __call__(self, x):
h = F.relu(conv1(x))
h = F.max_pooling_2d(h, 2)
h = F.relu(conv2(h))
h = F.max_pooling_2d(h, 2)
return h
model = SimpleCNN()
print('input image.shape', image.shape)
out_image = model(image).data
print('out_image.shape', out_image.shape)
out_image = out_image[0].transpose(1, 2, 0)
plot_channels(out_image,
filepath=os.path.join(basedir, 'output_simple_cnn.jpg'))
input image.shape (1, 3, 360, 640)
out_image.shape (1, 5, 44, 79)
