利用Tensorflow实现胶囊网络(CapsNets)
基于Sara Sabour,Nicholas Frosst和Geoffrey E. Hinton(NIPS 2017)的论文: Dynamic Routing Between Capsules.
部分启发来自 Huadong Liao的实现 CapsNet-TensorFlow.
Imports
为了支持Python 2和Python 3:
from __future__ import division, print_function, unicode_literals
绘制图形
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
我们需要NumPy和TensorFlow:
import numpy as np
import tensorflow as tf
重现性
让我们重置默认计算图,以防重新运行此笔记本而不重新启动内核:
tf.reset_default_graph()
让我们设置随机种子,这样总是产生相同的输出:
np.random.seed(42)
tf.set_random_seed(42)
加载 MNIST 数据集
是的,我知道,这是MNIST。但是希望这个强大的想法能够在更大的数据集上工作,时间会证明这一点。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("data/")
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
让我们看看这些手写数字图像是什么样的:
n_samples = 5
plt.figure(figsize=(n_samples * 2, 3))
for index in range(n_samples):
plt.subplot(1, n_samples, index + 1)
sample_image = mnist.train.images[index].reshape(28, 28)
plt.imshow(sample_image, cmap="binary")
plt.axis("off")
plt.show()
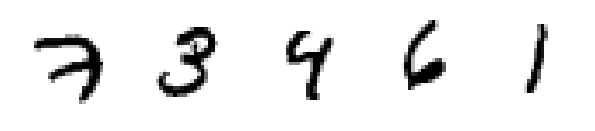
这些是相应的标签:
mnist.train.labels[:n_samples]
array([7, 3, 4, 6, 1], dtype=uint8)
现在让我们建立一个胶囊网络来分类这些图像。这是整体架构,为了便于阅读,我省略了两个箭头:标签→掩码,输入图像→重建损失。
损失
↑
┌─────────┴─────────┐
标签 → 边界损失 重构损失
↑ ↑
长度 解码器
↑ ↑
数字胶囊 ──── 掩膜 ────┘
↖↑↗ ↖↑↗ ↖↑↗
初级胶囊
↑
输入图像
我们要从底层开始建立计算图,然后逐渐向上移动,先从左边开始吧!
输入图像
我们首先为输入图像创建一个占位符(28×28像素,1个颜色通道=灰度)
X = tf.placeholder(shape=[None, 28, 28, 1], dtype=tf.float32, name="X")
主胶囊
第一层由32组胶囊组构成,每个胶囊组含有 6×6 个胶囊, 每个胶囊将输出8维激活向量:
caps1_n_maps = 32
caps1_n_caps = caps1_n_maps * 6 * 6 # 1152 个初级胶囊
caps1_n_dims = 8
为了计算它们的输出,我们首先应用两个常规的卷积层:
conv1_params = {
"filters": 256,
"kernel_size": 9,
"strides": 1,
"padding": "valid",
"activation": tf.nn.relu,
}
conv2_params = {
"filters": caps1_n_maps * caps1_n_dims, # 32*8 256 卷积滤波
"kernel_size": 9,
"strides": 2,
"padding": "valid",
"activation": tf.nn.relu
}
conv1 = tf.layers.conv2d(X, name="conv1", **conv1_params)
conv2 = tf.layers.conv2d(conv1, name="conv2", **conv2_params)
注意:因为我们使用了内核大小为9且非填充模式(有效的卷积输出),所以在图像经过每个卷积层每个维度都会缩小9-1个像素(28×28到20×20,然后20×20到12×12),由于在第二个卷积层中使用了大小为2的步幅,所以图像大小再除以2,这就是我们如何得到6×6个特征图。
接下来,我们重塑输出以获得表示主胶囊输出的一组8D向量。 conv2的输出是每个实例包含32×8 = 256个特征映射的数组,每个特征映射为6×6。所以这个输出的形状是(批次大小,6,6,256)。我们想把256个特征映射分成8个维度,每个维度含有32个向量。我们可以通过大小重塑(批次大小,6,6,32,8)来做到这一点。但是,由于这个第一个胶囊层将完全连接到下一个胶囊层,所以我们可以简单地将这个6×6个网格扁平化。这意味着我们只需要重塑大小为(批次大小,6×6×32,8)。
caps1_raw = tf.reshape(conv2, [-1, caps1_n_caps, caps1_n_dims],
name="caps1_raw")
现在我们需要压缩这些向量。让我们根据论文中等式(1)定义squash()函数:
squash() 函数将压缩给定数组中所有的矢量,沿给定的轴(默认情况下是最后一个轴)。
小心, 一个讨厌的bug正等着咬你:当$|\mathbf{s}| = 0 $时,$|\mathbf{s}|$的导数是不确定的,所以我们不能只使用tf.norm(),否则在训练过程中会 :如果一个向量是零,梯度将是nan,所以当优化器更新变量的时候,它们也会变成nan, 从那时起优化器就被困在NAN的空间里。解决的办法是通过计算平方和的平方根加上一个微小的epsilon值手动实现规范:
.
def squash(s, axis=-1, epsilon=1e-7, name=None):
with tf.name_scope(name, default_name="squash"):
squared_norm = tf.reduce_sum(tf.square(s), axis=axis,
keep_dims=True)
safe_norm = tf.sqrt(squared_norm + epsilon)
squash_factor = squared_norm / (1. + squared_norm)
unit_vector = s / safe_norm
return squash_factor * unit_vector
现在让我们应用这个函数来得到每个主胶囊$i$的输出$\mathbf{u}_i$:
caps1_output = squash(caps1_raw, name="caps1_output")
我们有第一个胶囊层的输出。这不是太难,是吗?然而,计算下一层是乐趣真正开始的地方。
数字胶囊
为了计算数字胶囊的输出,我们必须首先计算预测输出向量(每个主/数胶囊对一个)。然后我们可以通过协议算法来运行路由。
计算预测的输出向量
数字胶囊层包含10个胶囊(每个数字一个),每个胶囊含有16个维度的向量:
caps2_n_caps = 10
caps2_n_dims = 16
对于第一层中的每个胶囊 $i$ ,我们想要预测第二层中每个胶囊 $j$ 的输出。 为此,我们需要一个变换矩阵 $ \mathbf {W}_ {i,j} $, 每两个胶囊对应着($i$,$j$). 然后我们可以计算出预测的输出 $ \hat {\mathbf{u}} _ {j|i} = \mathbf {W}_ {i,j} \, \mathbf {u} _i $ (在论文中等式 (2)右边部分).由于我们想要将一个8D向量转换成一个16D向量,每个变换矩阵 $ \mathbf {W} _{i,j} $必须具有(16,8)的形状。
为了计算每一对胶囊($i$,$j$)的 $ \hat { \mathbf {u}} _ {j,i} $, 我们将使用tf.matmul()函数的一个很好的特性: 你可能知道它可以让你乘两个矩阵,但你可能不知道它也可以让你乘以更高维数组。它将数组视为矩阵数组,并执行逐项矩阵乘法。例如,假设您有两个4D阵列,每个阵列包含一个2×3的矩阵网格。第一个包含矩阵$\mathbf {A},\mathbf {B},\mathbf {C},\mathbf {D},\mathbf {E},\mathbf {F} $,第二个包含矩阵$ \mathbf { G},\mathbf {H},\mathbf {I},\mathbf {J},\mathbf {K},\mathbf {L} $。如果你用tf.matmul()函数把这两个4D数组相乘,就得到了这个结果:
我们可以应用这个函数来计算每一对胶囊($i$,$j$)的$ \hat {\mathbf {u}}_ {j,i} $(记得有第一层1152个胶囊(6×6×32),第二层10个):
第一阵列的形状是(1152,10,16,8),第二阵列的形状是(1152,10,8,1)。请注意,第二个数组必须包含10个相同的向量$ \mathbf {u} _1 $到$ \mathbf{u} _ {1152} $。为了创建这个数组,我们将使用方便的tf.tile()函数,它可以让你创建一个包含许多基本数组副本的数组,以任何你想要的方式平铺。
哦,等一下!我们忘了一个维度:批次大小。假设我们向胶囊网络提供50个图像,它将同时预测这50个图像。所以第一个数组的形状必须是(50,1152,10,16,8),而第二个数组的形状必须是(50,1152,10,8,1)。第一层胶囊实际上已经输出了所有50张图像的预测,所以第二个数组会很好,但是对于第一个数组,我们需要使用tf.tile()有50个变换矩阵的副本。
好吧,让我们开始创建一个形状为(1,1152,10,16,8)可训练变量,它将保存所有的变换矩阵。第一个维度为1, 这将使这个数组容易平铺。我们随机使用标准差为0.01的正态分布初始化这个变量。
init_sigma = 0.01
W_init = tf.random_normal(
shape=(1, caps1_n_caps, caps2_n_caps, caps2_n_dims, caps1_n_dims),
stddev=init_sigma, dtype=tf.float32, name="W_init")
W = tf.Variable(W_init, name="W")
现在我们可以通过每个实例重复一次W来创建第一个数组:
batch_size = tf.shape(X)[0]
W_tiled = tf.tile(W, [batch_size, 1, 1, 1, 1], name="W_tiled")
到第二个数组,现在。如前所述,我们需要创建一个形状(批次大小,1152,10,8,1)的数组,其中包含第一层胶囊的输出,重复10次(每个数字一次,沿着第三维,即轴= 2)。 caps1_output数组的形状是(批次大小,1152,8),所以我们首先需要扩展两次,得到一个形状数组(批次大小,1152,1,8,1),然后我们可以重复它沿着第三维10倍:
caps1_output_expanded = tf.expand_dims(caps1_output, -1,
name="caps1_output_expanded")
caps1_output_tile = tf.expand_dims(caps1_output_expanded, 2,
name="caps1_output_tile")
caps1_output_tiled = tf.tile(caps1_output_tile, [1, 1, caps2_n_caps, 1, 1],
name="caps1_output_tiled")
我们来检查第一个数组的形状
W_tiled
<tf.Tensor 'W_tiled:0' shape=(?, 1152, 10, 16, 8) dtype=float32>
现在第二个:
caps1_output_tiled
<tf.Tensor 'caps1_output_tiled:0' shape=(?, 1152, 10, 8, 1) dtype=float32>
现在,为了得到所有的预测输出向量$\hat{\mathbf{u}}_{j,i}$,我们只需要用tf.matmul()乘以这两个数组,如前所述:
caps2_predicted = tf.matmul(W_tiled, caps1_output_tiled,
name="caps2_predicted")
让我们来看看形状:
caps2_predicted
<tf.Tensor 'caps2_predicted:0' shape=(?, 1152, 10, 16, 1) dtype=float32>
对于批次中的每个实例(我们还不知道批量大小,因此是“?”),并且对于每对第一和第二层胶囊(1152×10),我们具有16D预测输出列向量(16 ×1)。下面我们准备应用路由协议算法!
路由协议
首先让我们将原始路由权重$b_{i,j}$初始化为零
raw_weights = tf.zeros([batch_size, caps1_n_caps, caps2_n_caps, 1, 1],
dtype=np.float32, name="raw_weights")
我们将会看到为什么我们需要将最后两个维度设定为1。
第 1 轮
首先,我们应用softmax函数来计算路由权重,如下所示: $\mathbf{c}_{i} = \operatorname{softmax}(\mathbf{b}_i)$ (论文中的等式 (3)):
routing_weights = tf.nn.softmax(raw_weights, dim=2, name="routing_weights")
现在我们来计算第二层每个胶囊的所有预测输出向量的加权和, $\mathbf{s}j = \sum\limits{i}{c_{i,j}\hat{\mathbf{u}}_{j,i}}$ (论文中等式(2)的左边):
weighted_predictions = tf.multiply(routing_weights, caps2_predicted,
name="weighted_predictions")
weighted_sum = tf.reduce_sum(weighted_predictions, axis=1, keep_dims=True,
name="weighted_sum")
这里有几个重要的细节需要注意:
-
为了执行元素矩阵乘法(也称为Hadamard乘积,记做$\circ$),我们使用
tf.multiply()函数。它要求routing_weights和caps2_predicted具有相同的大小,这就是为什么我们在前面为routing_weights添加了两个额外的维度1的原因。 -
“routing_weights”的形状是(批次大小,1152,10,1,1),而
caps2_predicted的形状是(批次大小,1152,10,16,1)。由于它们在第四维(1 vs 16)上不匹配,所以tf.multiply()自动沿着该维度广播routing_weights16次。如果您不熟悉广播,一个简单的例子可能会有所帮助:
最后,让我们应用压缩函数在协议算法的第一次迭代结束时得到第二层胶囊的输出, $\mathbf{v}_j = \operatorname{squash}(\mathbf{s}_j)$ :
caps2_output_round_1 = squash(weighted_sum, axis=-2,
name="caps2_output_round_1")
caps2_output_round_1
<tf.Tensor 'caps2_output_round_1/mul:0' shape=(?, 1, 10, 16, 1) dtype=float32>
按照预期,每个实例都有十个16D输出向量。
第 2 轮
首先,通过标量乘积$ \hat { \mathbf{u} } _{j,i} \cdot \mathbf{v} _j $来计算预测的向量 $ \hat{ \mathbf{u} } _{j,i} $ 与输出的向量 $ \mathbf{v} _j $之间的有多接近.
- 快速数学提示:如果$ \vec {a} $和$ \vec {b} $是两个长度相等的向量,$ \mathbf {a} $和$ \mathbf {b} $是它们对应的列向量(即单列矩阵),则$ \mathbf {a} ^ T \mathbf {b} $ (也就是$ \mathbf {a} $ 和$ \mathbf {b} $的转置的矩阵乘法) ,是包含两个向量$ \vec {a} \cdot \vec {b} $的标量乘积的1×1矩阵。在机器学习中,我们一般将向量表示为列向量,所以当我们谈论计算标量积 $ \hat { \mathbf {u} } _{j,i} \cdot \mathbf{v} _j $时,这实际上意味着计算 $ { \hat { \mathbf{u} } _{j,i}} ^T \mathbf{v} _j$.
由于我们需要为每对第一和第二级胶囊对 $(i,j)$ 实例计算标量积 $ \hat { \mathbf{u} } _{j,i} \cdot \mathbf {v} _j$,我们将再一次利用tf.matmul()可以同时乘以许多矩阵的特性。这将需要使用tf.tile()来使得所有维度的匹配(除了最后2个),就像我们之前做的那样。所以让我们来看看caps2_predicted的形状,存储着每个实例和每对胶囊保存所有预测的输出向量$ \hat { \mathbf{u}} _{j,i}$
caps2_predicted
<tf.Tensor 'caps2_predicted:0' shape=(?, 1152, 10, 16, 1) dtype=float32>
现在让我们来看看caps2_output_round_1的形状,每个实例有10个输出向量,每个向量为16维:
caps2_output_round_1
<tf.Tensor 'caps2_output_round_1/mul:0' shape=(?, 1, 10, 16, 1) dtype=float32>
为了使这些形状相匹配,我们只需要在第二个维度上将“caps2_output_round_1”数组平铺1152次(每个主胶囊一次)
caps2_output_round_1_tiled = tf.tile(
caps2_output_round_1, [1, caps1_n_caps, 1, 1, 1],
name="caps2_output_round_1_tiled")
现在我们准备调用tf.matmul()(注意,我们必须告诉它把第一个数组中的矩阵转置,得到${\mathbf {u}}_{j , i}^T$而不是$ \hat {\mathbf {u}} _ {j , i} $):
agreement = tf.matmul(caps2_predicted, caps2_output_round_1_tiled,
transpose_a=True, name="agreement")
现在我们可以通过简单地加上标量积来更新原始路由权重(参见该论文的过程1,步骤7,)。
raw_weights_round_2 = tf.add(raw_weights, agreement,
name="raw_weights_round_2")
第2轮的其余部分与第1轮相同:
routing_weights_round_2 = tf.nn.softmax(raw_weights_round_2,
dim=2,
name="routing_weights_round_2")
weighted_predictions_round_2 = tf.multiply(routing_weights_round_2,
caps2_predicted,
name="weighted_predictions_round_2")
weighted_sum_round_2 = tf.reduce_sum(weighted_predictions_round_2,
axis=1, keep_dims=True,
name="weighted_sum_round_2")
caps2_output_round_2 = squash(weighted_sum_round_2,
axis=-2,
name="caps2_output_round_2")
我们可以重复几次,重复与第2轮完全相同的步骤,但为了保持简短,我们将停在这里:
caps2_output = caps2_output_round_2
静态或动态循环?
在上面的代码中,我们在TensorFlow计算图中为协调算法的每一轮路由创建了不同的操作。换句话说,这是一个静态的循环。
当然,不是复制/粘贴代码几次,我们可以在Python中编写一个for循环,但是这不会改变这样一个事实,即图形最终将包含对于每个路由迭代的不同操作。实际上,因为我们通常只需要少于5次的路由迭代,所以图形不会变得太大。
但是,您可能更喜欢在TensorFlow计算图本身内部实现路由循环,而不是使用Python for 循环。要做到这一点,你需要使用TensorFlow的tf.while_loop()函数。这样,所有的路由迭代将在图中重复使用相同的操作,这将是一个动态循环。
例如,下面是如何构建一个计算从1到100的平方和的小循环:
def condition(input, counter):
return tf.less(counter, 100)
def loop_body(input, counter):
output = tf.add(input, tf.square(counter))
return output, tf.add(counter, 1)
with tf.name_scope("compute_sum_of_squares"):
counter = tf.constant(1)
sum_of_squares = tf.constant(0)
result = tf.while_loop(condition, loop_body, [sum_of_squares, counter])
with tf.Session() as sess:
print(sess.run(result))
(328350, 100)
正如你所看到的,tf.while_loop()函数需要通过两个函数来提供循环条件和循环体。这些函数在TensorFlow中只会被调用一次,在计算图构建阶段,在执行计算图的时候不会被调用。 tf.while_loop()函数将由condition()和loop_body()创建的图形片段连同一些额外的操作一起缝合来创建循环。
另外请注意,在训练过程中,TensorFlow将自动处理通过循环的反向传播,因此您不必担心这一点。
当然,我们可以使用这个单一的循环!
sum([i**2 for i in range(1, 100 + 1)])
338350
除了减小计算图大小外,使用动态循环而不是静态循环可以帮助减少GPU RAM的使用(如果使用GPU)。事实上,如果在调用tf.while_loop()函数时设置swap_memory = True,TensorFlow会在每次循环迭代时自动检查GPU RAM的使用情况,并在需要时处理GPU和CPU之间的内存交换。由于CPU内存比GPU内存要便宜和丰富,所以这确实可以起到很大的作用。
估计类的概率 (长度)
输出向量的长度表示类的概率,所以我们可以使用tf.norm()来计算它们,但是正如我们在讨论squash函数时所看到的那样,这将是有风险的,所以让我们创建自己的safe_norm()函数:
def safe_norm(s, axis=-1, epsilon=1e-7, keep_dims=False, name=None):
with tf.name_scope(name, default_name="safe_norm"):
squared_norm = tf.reduce_sum(tf.square(s), axis=axis,
keep_dims=keep_dims)
return tf.sqrt(squared_norm + epsilon)
y_proba = safe_norm(caps2_output, axis=-2, name="y_proba")
为了预测每个实例的类别,我们可以选择具有最高估计概率的类别。要做到这一点,我们首先使用tf.argmax()来找到它的索引:
y_proba_argmax = tf.argmax(y_proba, axis=2, name="y_proba")
我们来看看y_proba_argmax的形状:
y_proba_argmax
<tf.Tensor 'y_proba_1:0' shape=(?, 1, 1) dtype=int64>
这就是我们想要的:对于每个实例,我们现在有最长输出向量的索引。让我们通过使用tf.squeeze()去掉尺寸为1的尺寸的最后两个维度。这给了我们每个实例的胶囊网络的预测类:
y_pred = tf.squeeze(y_proba_argmax, axis=[1,2], name="y_pred")
y_pred
<tf.Tensor 'y_pred:0' shape=(?,) dtype=int64>
我们现在准备好定义训练操作,从损失开始。
标签
首先,我们需要一个标签的占位符:
y = tf.placeholder(shape=[None], dtype=tf.int64, name="y")
边界损失
原来的论文中使用一个特殊的边界损失以便在每个图像中能够检测的两个或更多不同的数字:
$ L_k = T_k \max(0, m^{+} - |\mathbf{v}_k|)^2 + \lambda (1 - T_k) \max(0, |\mathbf{v}_k| - m^{-})^2$
- $T_k$ 等于1,如果$k$类的数字存在,否则为0。
- 在论文中 $m^{+} = 0.9$, $m^{-} = 0.1$ 并且 $\lambda = 0.5$.
m_plus = 0.9
m_minus = 0.1
lambda_ = 0.5
由于y将包含数字类,从0到9,为了获得每个实例和每个类的$T_k$,我们可以使用tf.one_hot()函数:
T = tf.one_hot(y, depth=caps2_n_caps, name="T")
一个小例子应该清楚这是做什么的:
with tf.Session():
print(T.eval(feed_dict={y: np.array([0, 1, 2, 3, 9])}))
[[ 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]
现在我们来计算每个输出胶囊和每个实例的输出向量的范数。首先,我们来验证caps2_output的形状:
caps2_output
<tf.Tensor 'caps2_output_round_2/mul:0' shape=(?, 1, 10, 16, 1) dtype=float32>
在倒数第二个维度是16维的输出向量,故使用带参数axis=-2的safe_norm()函数来计算其范数:
caps2_output_norm = safe_norm(caps2_output, axis=-2, keep_dims=True,
name="caps2_output_norm")
现在我们计算 $\max(0, m^{+} - |\mathbf{v}_k|)^2$, 并将其重塑为一个大小为 (批次大小, 10) 的简单矩阵:
present_error_raw = tf.square(tf.maximum(0., m_plus - caps2_output_norm),
name="present_error_raw")
present_error = tf.reshape(present_error_raw, shape=(-1, 10),
name="present_error")
现在我们计算 $\max(0, |\mathbf{v}_k| - m^{-})^2$ 并且重塑它:
absent_error_raw = tf.square(tf.maximum(0., caps2_output_norm - m_minus),
name="absent_error_raw")
absent_error = tf.reshape(absent_error_raw, shape=(-1, 10),
name="absent_error")
我们现在准备好计算每个实例和数字之间的损失:
L = tf.add(T * present_error, lambda_ * (1.0 - T) * absent_error,
name="L")
现在我们可以汇总每个实例的数字损失($ L_0 + L_1 + \cdots + L_9 $),并计算所有实例的平均值。这给了我们最终的边界损失:
margin_loss = tf.reduce_mean(tf.reduce_sum(L, axis=1), name="margin_loss")
重构
现在让我们在胶囊网络的顶部添加一个解码器网络。它是一个常规的三层全连接神经网络,将学习基于胶囊网络的输出重建输入图像。这将迫使胶囊网络在整个网络上保存重建数字所需的所有信息。这个约束规范了模型:它减少了过度拟合训练集的风险,并且有助于泛化到新的数字。
掩膜
在Hinton的论文中提到,在训练过程中,我们不必将胶囊网络的所有输出发送到解码器网络,而只需要发送与目标数字对应的胶囊的输出矢量。所有其他输出向量必须被屏蔽掉。在推理时,我们除了最长的输出矢量,其他的输出都将被掩盖,即对应于预测数字的输出矢量。您可以在论文的图2中看到这一点:除了重建目标的输出向量之外,所有输出向量都被屏蔽掉。
我们需要一个占位符来告诉TensorFlow我们是否想根据标签(True)或者预测(False,默认值)掩盖输出向量
mask_with_labels = tf.placeholder_with_default(False, shape=(),
name="mask_with_labels")
现在让我们使用tf.cond()将重建目标定义为标签y,如果mask_with_labels为True,否则就是y_pred
reconstruction_targets = tf.cond(mask_with_labels, # condition
lambda: y, # if True
lambda: y_pred, # if False
name="reconstruction_targets")
请注意,tf.cond()函数需要 通过 函数传递if-True和if-False张量:这些函数在图构建阶段(不是在执行阶段)只会被调用一次, 和tf.while_loop()很相似。这允许TensorFlow添加必要的操作来处理if-True或If-False张量的条件评估。然而,在我们的例子中,张量y和y_pred已经在我们调用tf.cond()的时候被创建了,所以不幸的是TensorFlow会把y和y_pred看作是依赖于reconstruction_targets 张量.reconstruction_targets 张量将得到正确的值,但是:
- 只要我们评估一个依赖于
reconstruction_targets的张量,就会评估y_pred张量(即使mask_with_layers是True)。这不是什么大问题,因为计算y_pred在训练过程中不会增加计算开销,因为无论如何我们都需要计算边际损失。而在测试过程中,如果我们正在进行分类,我们不需要重建,所以rebuild_targets根本不会被评估。 - 我们将始终需要为
y占位符提供值(即使mask_with_layers为False)。这有点烦人,但是我们可以传递一个空的数组,因为TensorFlow不会使用它(当它检查依赖时,它只是不知道它)。
现在我们有了重建目标,我们来创建重建蒙板。对于目标类,它应该等于1.0,对于其他类,对于每个实例,应该等于0.0。为此,我们可以使用tf.one_hot()函数:
reconstruction_mask = tf.one_hot(reconstruction_targets,
depth=caps2_n_caps,
name="reconstruction_mask")
我们来检查一下reconstruction_mask的形状:
reconstruction_mask
<tf.Tensor 'reconstruction_mask:0' shape=(?, 10) dtype=float32>
我们来比较一下caps2_output的形状:
caps2_output
<tf.Tensor 'caps2_output_round_2/mul:0' shape=(?, 1, 10, 16, 1) dtype=float32>
嗯,它的形状是(批次大小,1,10,16,1)。我们想用reconstruction_mask乘以它,但reconstruction_mask的形状是(批次大小,10)。我们必须重塑它为(批次大小,1,10,1,1)以使乘法成为可能:
reconstruction_mask_reshaped = tf.reshape(
reconstruction_mask, [-1, 1, caps2_n_caps, 1, 1],
name="reconstruction_mask_reshaped")
最后!我们可以应用掩膜:
caps2_output_masked = tf.multiply(
caps2_output, reconstruction_mask_reshaped,
name="caps2_output_masked")
caps2_output_masked
<tf.Tensor 'caps2_output_masked:0' shape=(?, 1, 10, 16, 1) dtype=float32>
最后一次重塑操作来平整解码器的输入:
decoder_input = tf.reshape(caps2_output_masked,
[-1, caps2_n_caps * caps2_n_dims],
name="decoder_input")
获得了一个形状的数组(批次大小,160):
decoder_input
<tf.Tensor 'decoder_input:0' shape=(?, 160) dtype=float32>
解码器
现在我们来构建解码器。这很简单:两个密集(完全连接)的ReLU层紧跟着一个密集输出S形层:
n_hidden1 = 512
n_hidden2 = 1024
n_output = 28 * 28
with tf.name_scope("decoder"):
hidden1 = tf.layers.dense(decoder_input, n_hidden1,
activation=tf.nn.relu,
name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2,
activation=tf.nn.relu,
name="hidden2")
decoder_output = tf.layers.dense(hidden2, n_output,
activation=tf.nn.sigmoid,
name="decoder_output")
重构损失
现在我们来计算重构损失。这只是输入图像和重构图像之间的平方差:
X_flat = tf.reshape(X, [-1, n_output], name="X_flat")
squared_difference = tf.square(X_flat - decoder_output,
name="squared_difference")
reconstruction_loss = tf.reduce_sum(squared_difference,
name="reconstruction_loss")
最终损失
最终损失是边界损失和重构损失的总和(按比例缩小0.0005倍以确保边界损失主导着训练):
alpha = 0.0005
loss = tf.add(margin_loss, alpha * reconstruction_loss, name="loss")
最终润色
准确性
为了衡量我们的模型的准确性,我们需要计算正确分类的实例的数量。为此,我们可以简单地比较y和y_pred,将布尔值转换为float32(False为0.0,True为True),并计算所有实例的平均值:
correct = tf.equal(y, y_pred, name="correct")
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
训练操作
原来的论文作者使用了TensorFlow的默认参数Adam优化器:
optimizer = tf.train.AdamOptimizer()
training_op = optimizer.minimize(loss, name="training_op")
初始化和保存器
让我们添加通常的变量初始值设定项,以及一个Saver:
init = tf.global_variables_initializer()
saver = tf.train.Saver()
我们已经完成了构造阶段!请花一点时间来庆祝。 :)
训练
训练我们的胶囊网络过程是非常标准的。为了简单起见,我们不会做任何花哨的超参数调整,dropout或任何其他操作,我们将一遍又一遍地运行训练操作,显示损失,并在每个epoch结束时,测量验证集的精度,显示如果验证损失是迄今为止发现的最低值(这是实现提前停止的基本方法,而不实际停止),则保存模型。希望代码应该是不言自明的,但是这里有一些细节需要注意:
- 如果检查点文件存在,它将被恢复(这可以中断训练,然后从上一个检查点稍后重新启动),
- 我们不能忘记在训练期间提供
mask_with_labels = True, - 在测试过程中,我们将
mask_with_labels默认为False(但是由于需要计算精确度,我们仍然会提供这些标签), - 通过
mnist.train.next_batch()加载的的图像被表示为形状为[784 ]的float32数组,但是输入占位符X需要的形状为[ 28,28, 1 ],所以我们必须在将图像进行重塑以适应需求, - 我们在完整的验证集(5,000个实例)上评估模型的损失和准确性。由于有的系统的 RAM 容量不够大,代码分批次的进行损失和准确性的评估,最后计算平均损失和平均准确度。
警告:如果你没有GPU,训练将需要很长时间(至少几个小时)。使用GPU时,每个 epoch 应该只需要几分钟(例如,在NVidia GeForce GTX 1080Ti上6分钟)。
n_epochs = 10
batch_size = 50
restore_checkpoint = True
n_iterations_per_epoch = mnist.train.num_examples // batch_size
n_iterations_validation = mnist.validation.num_examples // batch_size
best_loss_val = np.infty
checkpoint_path = "./my_capsule_network"
with tf.Session() as sess:
if restore_checkpoint and tf.train.checkpoint_exists(checkpoint_path):
saver.restore(sess, checkpoint_path)
else:
init.run()
for epoch in range(n_epochs):
for iteration in range(1, n_iterations_per_epoch + 1):
X_batch, y_batch = mnist.train.next_batch(batch_size)
# Run the training operation and measure the loss:
_, loss_train = sess.run(
[training_op, loss],
feed_dict={X: X_batch.reshape([-1, 28, 28, 1]),
y: y_batch,
mask_with_labels: True})
print("\rIteration: {}/{} ({:.1f}%) Loss: {:.5f}".format(
iteration, n_iterations_per_epoch,
iteration * 100 / n_iterations_per_epoch,
loss_train),
end="")
# At the end of each epoch,
# measure the validation loss and accuracy:
loss_vals = []
acc_vals = []
for iteration in range(1, n_iterations_validation + 1):
X_batch, y_batch = mnist.validation.next_batch(batch_size)
loss_val, acc_val = sess.run(
[loss, accuracy],
feed_dict={X: X_batch.reshape([-1, 28, 28, 1]),
y: y_batch})
loss_vals.append(loss_val)
acc_vals.append(acc_val)
print("\rEvaluating the model: {}/{} ({:.1f}%)".format(
iteration, n_iterations_validation,
iteration * 100 / n_iterations_validation),
end=" " * 10)
loss_val = np.mean(loss_vals)
acc_val = np.mean(acc_vals)
print("\rEpoch: {} Val accuracy: {:.4f}% Loss: {:.6f}{}".format(
epoch + 1, acc_val * 100, loss_val,
" (improved)" if loss_val < best_loss_val else ""))
# And save the model if it improved:
if loss_val < best_loss_val:
save_path = saver.save(sess, checkpoint_path)
best_loss_val = loss_val
INFO:tensorflow:Restoring parameters from ./my_capsule_network
Epoch: 1 Val accuracy: 99.4200% Loss: 0.163132 (improved)
Epoch: 2 Val accuracy: 99.3800% Loss: 0.160907 (improved)
Epoch: 3 Val accuracy: 99.4200% Loss: 0.159608 (improved)
Epoch: 4 Val accuracy: 99.4600% Loss: 0.157126 (improved)
Epoch: 5 Val accuracy: 99.4400% Loss: 0.154809 (improved)
Epoch: 6 Val accuracy: 99.4600% Loss: 0.154379 (improved)
Epoch: 7 Val accuracy: 99.3800% Loss: 0.153695 (improved)
Epoch: 8 Val accuracy: 99.4400% Loss: 0.152841 (improved)
Epoch: 9 Val accuracy: 99.4200% Loss: 0.152175 (improved)
Epoch: 10 Val accuracy: 99.4200% Loss: 0.151737 (improved)
训练完成后,我们在10个epoch后的验证集上达到了99.42%的准确率,看起来不错。现在让我们在测试集上评估模型。
评估
n_iterations_test = mnist.test.num_examples // batch_size
with tf.Session() as sess:
saver.restore(sess, checkpoint_path)
loss_tests = []
acc_tests = []
for iteration in range(1, n_iterations_test + 1):
X_batch, y_batch = mnist.test.next_batch(batch_size)
loss_test, acc_test = sess.run(
[loss, accuracy],
feed_dict={X: X_batch.reshape([-1, 28, 28, 1]),
y: y_batch})
loss_tests.append(loss_test)
acc_tests.append(acc_test)
print("\rEvaluating the model: {}/{} ({:.1f}%)".format(
iteration, n_iterations_test,
iteration * 100 / n_iterations_test),
end=" " * 10)
loss_test = np.mean(loss_tests)
acc_test = np.mean(acc_tests)
print("\rFinal test accuracy: {:.4f}% Loss: {:.6f}".format(
acc_test * 100, loss_test))
INFO:tensorflow:Restoring parameters from ./my_capsule_network
Final test accuracy: 99.3600% Loss: 0.154331
测试集的精度达到了99.36%。很不错。 :)
预测
现在让我们做一些预测!我们首先从测试集中固定选择一些图像,然后开始一个会话,恢复训练好的模型,计算caps2_output来得到胶囊网络的输出向量,decode_output来获得重构,y_pred得到类预测:
n_samples = 5
sample_images = mnist.test.images[:n_samples].reshape([-1, 28, 28, 1])
with tf.Session() as sess:
saver.restore(sess, checkpoint_path)
caps2_output_value, decoder_output_value, y_pred_value = sess.run(
[caps2_output, decoder_output, y_pred],
feed_dict={X: sample_images,
y: np.array([], dtype=np.int64)})
INFO:tensorflow:Restoring parameters from ./my_capsule_network
注意:我们用一个空数组提供y,但TensorFlow将不会使用它,如前所述。
现在让我们绘制图像及其标签,然后进行相应的重构和预测:
sample_images = sample_images.reshape(-1, 28, 28)
reconstructions = decoder_output_value.reshape([-1, 28, 28])
plt.figure(figsize=(n_samples * 2, 3))
for index in range(n_samples):
plt.subplot(1, n_samples, index + 1)
plt.imshow(sample_images[index], cmap="binary")
plt.title("Label:" + str(mnist.test.labels[index]))
plt.axis("off")
plt.show()
plt.figure(figsize=(n_samples * 2, 3))
for index in range(n_samples):
plt.subplot(1, n_samples, index + 1)
plt.title("Predicted:" + str(y_pred_value[index]))
plt.imshow(reconstructions[index], cmap="binary")
plt.axis("off")
plt.show()
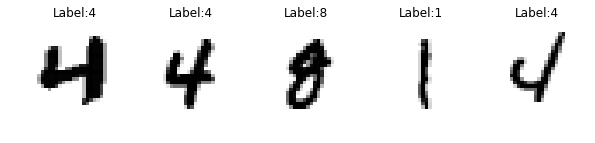
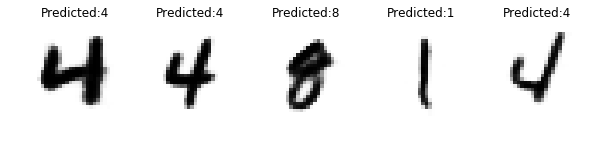
预测都是正确的,重构看起来很棒。
解释输出向量
让我们调整输出向量,看看他们的姿势参数代表什么。
首先,我们来看一下cap2_output_value NumPy数组的形状:
caps2_output_value.shape
(5, 1, 10, 16, 1)
让我们创建一个函数来调整所有输出向量中的16个姿态参数(维度)。每个调整后的输出矢量将与原始输出矢量相同,只是其中一个姿态参数将增加一个从-0.5变化到0.5的值。默认情况下会有11个步进值(-0.5,-0.4,…,+ 0.4,+ 0.5)。这个函数将返回一个形状数组(tweaked pose parameters = 16,steps = 11,batch size = 5,1,10,16,1):
def tweak_pose_parameters(output_vectors, min=-0.5, max=0.5, n_steps=11):
steps = np.linspace(min, max, n_steps) # -0.25, -0.15, ..., +0.25
pose_parameters = np.arange(caps2_n_dims) # 0, 1, ..., 15
tweaks = np.zeros([caps2_n_dims, n_steps, 1, 1, 1, caps2_n_dims, 1])
tweaks[pose_parameters, :, 0, 0, 0, pose_parameters, 0] = steps
output_vectors_expanded = output_vectors[np.newaxis, np.newaxis]
return tweaks + output_vectors_expanded
让我们计算所有调整后的输出向量,并将结果重新整形(parameters×steps×instances,1,10,16,1),以便我们可以将数组馈送到解码器:
n_steps = 11
tweaked_vectors = tweak_pose_parameters(caps2_output_value, n_steps=n_steps)
tweaked_vectors_reshaped = tweaked_vectors.reshape(
[-1, 1, caps2_n_caps, caps2_n_dims, 1])
现在,让我们将这些调整后的输出向量反馈给解码器,并获取它所产生的重构:
tweak_labels = np.tile(mnist.test.labels[:n_samples], caps2_n_dims * n_steps)
with tf.Session() as sess:
saver.restore(sess, checkpoint_path)
decoder_output_value = sess.run(
decoder_output,
feed_dict={caps2_output: tweaked_vectors_reshaped,
mask_with_labels: True,
y: tweak_labels})
INFO:tensorflow:Restoring parameters from ./my_capsule_network
让我们重塑解码器的输出,以便我们可以在输出维度上轻松地迭代,调整步骤和实例:
tweak_reconstructions = decoder_output_value.reshape(
[caps2_n_dims, n_steps, n_samples, 28, 28])
最后,我们为每个调整步骤(列)和每个数字(行)绘制所有重建的前3个输出维度
for dim in range(3):
print("Tweaking output dimension #{}".format(dim))
plt.figure(figsize=(n_steps / 1.2, n_samples / 1.5))
for row in range(n_samples):
for col in range(n_steps):
plt.subplot(n_samples, n_steps, row * n_steps + col + 1)
plt.imshow(tweak_reconstructions[dim, col, row], cmap="binary")
plt.axis("off")
plt.show()
Tweaking output dimension #0

Tweaking output dimension #1

Tweaking output dimension #2

结论
我试图使这个笔记本中的代码尽可能平坦和线性,以便更容易遵循,但是当然在实践中,您会想要将代码封装在很好的可重用函数和类中。例如,您可以尝试实现您自己的PrimaryCapsuleLayer和DenseRoutingCapsuleLayer类,其中包含胶囊数量,路由迭代次数,是否使用动态循环或静态循环等等。例如,基于TensorFlow的胶囊网络的模块化实现,请看CapsNet-TensorFlow项目。