基于训练的模型进行测试
from __future__ import print_function
import argparse
import time
import numpy as np
import six
import matplotlib.pyplot as plt
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import Chain, Variable, optimizers, serializers
from chainer import datasets, training, cuda, computational_graph
from chainer.dataset import concat_examples
from chainer import reporter
原来教程7所定义的网络
class MyMLP(chainer.Chain):
def __init__(self, n_units):
super(MyMLP, self).__init__()
with self.init_scope():
# the size of the inputs to each layer will be inferred
self.l1 = L.Linear(n_units) # n_in -> n_units
self.l2 = L.Linear(n_units) # n_units -> n_units
self.l3 = L.Linear(n_units) # n_units -> n_units
self.l4 = L.Linear(1) # n_units -> n_out
def __call__(self, *args):
# Calculate loss
h = self.forward(*args)
t = args[1]
self.loss = F.mean_squared_error(h, t)
reporter.report({'loss': self.loss}, self)
return self.loss
def forward(self, *args):
# Common code for both loss (__call__) and predict
x = args[0]
h = F.sigmoid(self.l1(x))
h = F.sigmoid(self.l2(h))
h = F.sigmoid(self.l3(h))
h = self.l4(h)
return h
def predict(self, *args):
with chainer.using_config('train', False):
with chainer.no_backprop_mode():
return self.forward(*args)
def predict2(self, *args, batchsize=32):
data = args[0]
x_list = []
y_list = []
t_list = []
for i in range(0, len(data), batchsize):
x, t = concat_examples(data[i:i + batchsize])
y = self.predict(x)
y_list.append(y.data)
x_list.append(x)
t_list.append(t)
x_array = np.concatenate(x_list)[:, 0]
y_array = np.concatenate(y_list)[:, 0]
t_array = np.concatenate(t_list)[:, 0]
return x_array, y_array, t_array
原来教程7定义的自定义数据集
class MyDataset(chainer.dataset.DatasetMixin):
def __init__(self, filepath, debug=False):
self.debug = debug
# Load the data in initialization
df = pd.read_csv(filepath)
self.data = df.values.astype(np.float32)
if self.debug:
print('[DEBUG] data: \n{}'.format(self.data))
def __len__(self):
"""return length of this dataset"""
return len(self.data)
def get_example(self, i):
"""Return i-th data"""
x, t = self.data[i]
return [x], [t]
命令行参数解析
parser = argparse.ArgumentParser(description='Chainer example: MNIST')
parser.add_argument('--modelpath', '-m', default='result/mymlp.model',
help='Model path to be loaded')
parser.add_argument('--gpu', '-g', type=int, default=-1,
help='GPU ID (negative value indicates CPU)')
parser.add_argument('--unit', '-u', type=int, default=50,
help='Number of units')
parser.add_argument('--batchsize', '-b', type=int, default=10,
help='Number of images in each mini-batch')
_StoreAction(option_strings=['--batchsize', '-b'], dest='batchsize', nargs=None, const=None, default=10, type=<class 'int'>, choices=None, help='Number of images in each mini-batch', metavar=None)
在Notebook中如果要使用这种命令行参数,将列表输入参数
args = parser.parse_args(['-g','0'])
获得命令行参数中的batchsize
batchsize = args.batchsize
import pandas as pd
dataset = MyDataset('data/my_data.csv')
train_ratio = 0.7
train_size = int(len(dataset) * train_ratio)
train, test = chainer.datasets.split_dataset_random(dataset, train_size, seed=13)
训练数据占70%,测试数据占30%,我们这里只关心测试数据。
model = MyMLP(args.unit) # type: MyMLP
if args.gpu >= 0:
chainer.cuda.get_device(args.gpu).use() # Make a specified GPU current
model.to_gpu() # Copy the model to the GPU
xp = np if args.gpu < 0 else cuda.cupy
serializers.load_npz(args.modelpath, model)
载入训练好的模型,并将模型送入GPU中。
x_list = []
y_list = []
t_list = []
for i in range(0, len(test), batchsize):
x, t = concat_examples(test[i:i + batchsize])
x_gpu = cuda.to_gpu(x)
y = model.predict(x_gpu)
y_list.append(y.data.tolist())
x_list.append(x.tolist())
t_list.append(t.tolist())
x_test = np.concatenate(x_list)[:, 0]
y_test = np.concatenate(y_list)[:, 0]
t_test = np.concatenate(t_list)[:, 0]
用在GPU里的模型进行回归预测,注意一开始从测试数据集获取的数据是面向CPU的,不能直接传送到GPU供模型使用,要通过cuda.to_gpu这样的函数进行转换,才可以使用。
%matplotlib inline
plt.figure()
plt.plot(x_test, t_test, 'o', label='test actual')
plt.plot(x_test, y_test, 'o', label='test predict')
plt.legend()
plt.savefig('predict_gpu.png')
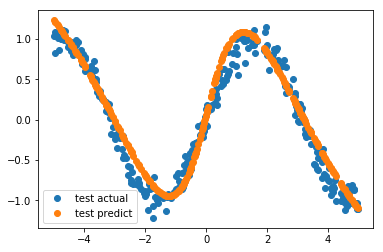
可以看到预测的结果和测试测结果,吻合度很高。