现代网络架构
在上一章中,我们探讨了深度学习算法如何用于创建艺术图像,基于现有数据集创建新图像以及生成文本。 在本章中,我们将向您介绍支持现代计算机视觉应用程序和自然语言系统的不同网络体系结构。 我们将在本章中讨论的一些架构是:
- 残差网络
- Inception
- DenseNet
- 编码器 - 解码器架构
现代网络架构
当深度学习模型无法学习时,我们做的重要事情之一是为模型添加更多层。 当您添加图层时,模型精度会提高,然后开始饱和。 随着您不断添加更多图层,它会开始降级。 添加超过一定数量的更多层将增加某些挑战,例如消失或爆炸渐变,这可通过仔细初始化权重和引入中间规范化层来部分解决。 现代架构,例如残差网络(ResNet)和Inception,试图通过引入不同的技术来解决这个问题,例如残差连接。
残差网络
残差网络通过添加快捷连接明确地让网络中的层适合残差映射来解决这些问题。 下图显示了ResNet的工作原理:

在我们看到的所有网络中,我们尝试通过堆叠不同的层来找到将输入(x)映射到其输出(H(x))的函数。 但ResNet的作者提出了修复方案; 而不是试图学习从x到H(x)的底层映射,我们学习了两者之间的差异,或者残差。 然后,为了计算H(x),我们可以将残差添加到输入中。 假设残差是F(x)= H(x) - x; 我们试图学习F(x)+ x,而不是试图直接学习H(x)。
每个ResNet块由一系列层组成,并且快捷连接将块的输入添加到块的输出。 添加操作是按元素级别操作的,输入和输出需要具有相同的大小。 如果它们的大小不同,那么我们可以使用填充。 以下代码演示了简单的ResNet块的实现:
import torch.nn as nn
import torch.nn.functional as F
class ResNetBasicBlock(nn.Module):
def __init__(self,in_channels,out_channels,stride):
super().__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=stride,padding=1,
bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride,padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.stride = stride
def forward(self,x):
residual = x
out = self.conv1(x)
out = F.relu(self.bn1(out),inplace=True)
out = self.conv2(out)
out = self.bn2(out)
out += residual
return F.relu(out)
ResNetBasicBlock包含一个初始化所有不同层的__init__方法,例如卷积层,批量标准化和ReLU层。 forward方法与我们迄今为止看到的方法几乎相似,只是输入在返回之前被添加回图层的输出。
PyTorch torchvision软件包提供了具有不同层的开箱即用的ResNet模型。 一些可用的不同类型是:
- RESNET-18
- RESNET-34
- RESNET-50
- RESNET-101
- RESNET-152
我们也可以使用这些模型中的任何一种进行迁移学习。 torchvision实例使我们能够简单地创建其中一个模型并使用它们。 我们已经在本书中做了几次,下面的代码是对此的复习:
from torchvision.models import resnet18
resnet = resnet18(pretrained=False)
下图显示了34层ResNet模型的外观:

我们可以看到这个网络如何由多个ResNet块组成。已经有过一些实验,团队已经尝试过1000层以上的模型。对于大多数真实世界的用例,我个人的建议是从较小的网络开始。这些现代网络的另一个关键优势是,与VGG等模型相比,它们只需要很少的参数,因为它们避免使用需要大量参数训练的完全连接的层。另一种用于解决计算机视觉领域问题的流行架构是Inception。在继续使用Inception体系结构之前,让我们在Dogs vs. Cats数据集上训练一个ResNet模型。我们将使用我们在第5章“计算机视觉的深度学习”中使用的数据,并将基于从ResNet计算的特征快速训练模型。像往常一样,我们将按照以下步骤训练模型:
- 创建PyTorch数据集
- 创建用于训练和验证的加载器
- 创建ResNet模型
- 提取卷积特征
- 为预卷积特征和加载器创建自定义PyTorch数据集类
- 创建简单的线性模型
- 训练和验证模型
完成后,我们将为Inception和DenseNet重复此步骤。最后,我们还将探索集成技术,我们将这些强大的模型结合起来构建一个新模型
创建PyTorch数据集
我们创建一个包含所需的所有基本转换的转换对象,并使用imageFolder从我们在第5章Deep Learning for Computer Vision中创建的数据目录中加载图像。 在以下代码中,我们创建数据集:
import pandas as pd
from glob import glob
import os
from shutil import copyfile
from torch.utils.data import Dataset
from PIL import Image
import numpy as np
from numpy.random import permutation
import matplotlib.pyplot as plt
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torchvision.models import resnet18,resnet34
from torchvision.models.inception import inception_v3
from torch.utils.data import DataLoader
from torch.autograd import Variable
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import pickle
%matplotlib inline
data_transform = transforms.Compose([
transforms.Resize((299,299)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# For Dogs & Cats dataset
train_dset = ImageFolder('../all/train/',transform=data_transform)
val_dset = ImageFolder('../all/valid/',transform=data_transform)
classes=2
到目前为止,大多数前面的代码都是不言自明的。
创建用于训练和验证的加载器
我们使用PyTorch加载器以批量的形式加载数据集提供的数据,以及所有优点,例如改组数据和使用多线程,以加快进程。 以下代码演示了这一点:
train_loader = DataLoader(train_dset,batch_size=32,shuffle=False,num_workers=3)
val_loader = DataLoader(val_dset,batch_size=32,shuffle=False,num_workers=3)
我们需要在计算预卷积特征时保持数据的确切顺序。 当我们允许数据被洗牌时,我们将无法维护标签。 因此,确保shuffle为False,否则需要在代码内写入处理所需的逻辑。
创建ResNet模型
使用resnet34预训练模型的图层,我们通过丢弃最后一个线性图层来创建PyTorch序列模型。 我们将使用此训练模型从图像中提取特征。 以下代码演示了这一点:
is_cuda = torch.cuda.is_available()
my_resnet = resnet34(pretrained=True)
if is_cuda:
my_resnet = my_resnet.cuda()
my_resnet = nn.Sequential(*list(my_resnet.children())[:-1])
for p in my_resnet.parameters():
p.requires_grad = False
在上面的代码中,我们创建了一个在torchvision模型中可用的resnet34模型。 在下一行中,我们选择除最后一层之外的所有ResNet层,并使用nn.Sequential创建一个新模型:
for p in my_resnet.parameters():
p.requires_grad = False
nn.Sequential实例允许我们使用一堆PyTorch层快速创建模型。 创建模型后,不要忘记将requires_grad参数设置为False,因为这将允许PyTorch不保留任何空间来保持梯度。
提取卷积特征
我们通过模型传递来自训练和验证数据加载器的数据,并将模型的结果存储在列表中以供进一步计算。 通过计算预卷积特征,我们可以节省大量训练模型的时间,因为我们不会在每次迭代中计算这些特征。 在以下代码中,我们计算预先卷积的特征:
#For training data
# Stores the labels of the train data
trn_labels = []
# Stores the pre convoluted features of the train data
trn_features = []
#Iterate through the train data and store the calculated features and the labels
for d,la in train_loader:
o = my_resnet(Variable(d.cuda()))
o = o.view(o.size(0),-1)
trn_labels.extend(la)
trn_features.extend(o.cpu().data)
#For validation data
#Iterate through the validation data and store the calculated features and the labels
val_labels = []
val_features = []
for d,la in val_loader:
o = my_resnet(Variable(d.cuda()))
o = o.view(o.size(0),-1)
val_labels.extend(la)
val_features.extend(o.cpu().data)
一旦我们计算了预卷积特征,我们就需要创建一个自定义数据集,该数据集可以从我们预先复杂的特征中选择数据。 让我们为预先复杂的特征创建一个自定义数据集和加载器。
为预卷积特征和加载器创建自定义PyTorch数据集类
我们已经了解了如何创建PyTorch数据集。 它应该是torch.utils.data数据集类的子类,并且应该实现getitem(self,index)和len(self)方法,这些方法返回数据集中数据的长度。 在以下代码中,我们为预卷积的特征实现了一个自定义数据集:
class FeaturesDataset(Dataset):
def __init__(self,featlst,labellst):
self.featlst = featlst
self.labellst = labellst
def __getitem__(self,index):
return (self.featlst[index],self.labellst[index])
def __len__(self):
return len(self.labellst)
创建自定义数据集类后,为预卷积特征创建数据加载器非常简单,如以下代码所示:
#Creating dataset for train and validation
trn_feat_dset = FeaturesDataset(trn_features,trn_labels)
val_feat_dset = FeaturesDataset(val_features,val_labels)
#Creating data loader for train and validation
trn_feat_loader = DataLoader(trn_feat_dset,batch_size=64,shuffle=True)
val_feat_loader = DataLoader(val_feat_dset,batch_size=64)
现在我们需要创建一个简单的线性模型,可以将预卷积的特征映射到相应的类别。
创建一个简单的线性模型
我们将创建一个简单的线性模型,将预先复杂的特征映射到相应的类别。 在这种情况下,类别的数量是两个:
class FullyConnectedModel(nn.Module):
def __init__(self,in_size,out_size):
super().__init__()
self.fc = nn.Linear(in_size,out_size)
def forward(self,inp):
out = self.fc(inp)
return out
fc_in_size = 8192
fc = FullyConnectedModel(fc_in_size,classes)
if is_cuda:
fc = fc.cuda()
optimizer = optim.Adam(fc.parameters(),lr=0.0001)
现在,我们可以很好地训练我们的新模型并验证数据集。
训练和验证模型
我们将使用与第5章“计算机视觉深度学习”中使用的相同的拟合函数。以下代码段包含训练模型并显示结果的功能:
def fit(epoch,model,data_loader,phase='training',volatile=False):
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , (data,target) in enumerate(data_loader):
if is_cuda:
data,target = data.cuda(),target.cuda()
data , target = Variable(data,volatile),Variable(target)
if phase == 'training':
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output,target)
running_loss += F.cross_entropy(output,target,size_average=False).data.item()
preds = output.data.max(dim=1,keepdim=True)[1]
running_correct += preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy}')
return loss,accuracy
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,20):
epoch_loss, epoch_accuracy = fit(epoch,fc,trn_feat_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,fc,val_feat_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
/Users/zhipingxu/anaconda3/lib/python3.6/site-packages/torch/nn/functional.py:52: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
training loss is 0.16 and training accuracy is 21893/2300095
validation loss is 0.17 and validation accuracy is 1874/200093
training loss is 0.15 and training accuracy is 21945/2300095
validation loss is 0.16 and validation accuracy is 1890/200094
training loss is 0.14 and training accuracy is 22031/2300095
validation loss is 0.14 and validation accuracy is 1907/200095
training loss is 0.14 and training accuracy is 22073/2300095
validation loss is 0.17 and validation accuracy is 1877/200093
training loss is 0.13 and training accuracy is 22124/2300096
validation loss is 0.14 and validation accuracy is 1911/200095
training loss is 0.12 and training accuracy is 22167/2300096
validation loss is 0.13 and validation accuracy is 1919/200095
training loss is 0.12 and training accuracy is 22153/2300096
validation loss is 0.12 and validation accuracy is 1922/200096
training loss is 0.12 and training accuracy is 22235/2300096
validation loss is 0.12 and validation accuracy is 1927/200096
training loss is 0.11 and training accuracy is 22243/2300096
validation loss is 0.12 and validation accuracy is 1926/200096
training loss is 0.11 and training accuracy is 22284/2300096
validation loss is 0.12 and validation accuracy is 1918/200095
training loss is 0.11 and training accuracy is 22297/2300096
validation loss is 0.12 and validation accuracy is 1923/200096
training loss is 0.1 and training accuracy is 22350/2300097
validation loss is 0.12 and validation accuracy is 1925/200096
training loss is 0.096 and training accuracy is 22362/2300097
validation loss is 0.11 and validation accuracy is 1932/200096
training loss is 0.096 and training accuracy is 22367/2300097
validation loss is 0.12 and validation accuracy is 1919/200095
training loss is 0.092 and training accuracy is 22416/2300097
validation loss is 0.12 and validation accuracy is 1919/200095
training loss is 0.09 and training accuracy is 22409/2300097
validation loss is 0.099 and validation accuracy is 1937/200096
training loss is 0.088 and training accuracy is 22439/2300097
validation loss is 0.11 and validation accuracy is 1928/200096
training loss is 0.085 and training accuracy is 22454/2300097
validation loss is 0.11 and validation accuracy is 1923/200096
training loss is 0.08 and training accuracy is 22504/2300097
validation loss is 0.091 and validation accuracy is 1937/200096
从结果中我们可以看出,该模型实现了98%的训练精度和96%的验证准确度。 让我们了解另一种现代架构以及如何使用它来计算预先复杂的特征并使用它们来训练模型。
Inception模块
在我们在计算机视觉模型中看到的大多数深度学习算法中,我们要么选择一个滤波器尺寸为1 x 1,3 x 3,5 x 5,7 x 7的卷积层,要么使用映射池化层。 Inception模块结合了不同滤波器大小的卷积,并将所有输出连接在一起。 下图使Inception模型更清晰:
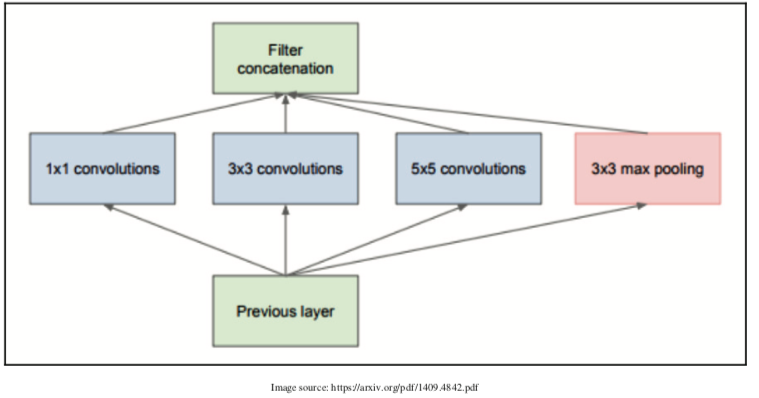
在此初始块图像中,将不同大小的卷积应用于输入,并且连接所有这些层的输出。 这是Inception模块的最简单版本。 还有另一种Inception块的变体,我们将输入通过1 x 1卷积,然后通过3 x 3和5 x 5卷积。 1 x 1卷积用于降维。 它有助于解决计算瓶颈。 1 x 1卷积一次查看一个值并跨越通道。 例如,在输入大小为100 x 64 x 64时使用10 x 1 x 1滤波器将产生10 x 64 x 64.下图显示了具有降维的Inception块:
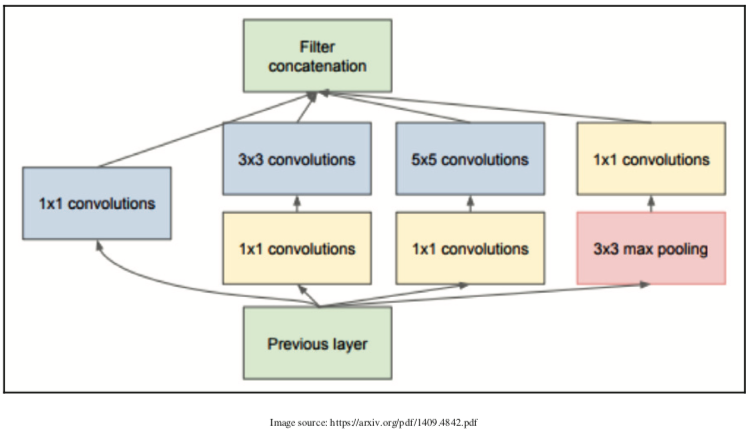
现在,让我们看一下前面的Inception块的PyTorch示例:
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class InceptionBasicBlock(nn.Module):
def __init__(self, in_channels, pool_features):
super().__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
上面的代码包含两个类,BasicConv2d和inceptionBasicBlock。 BasicConv2d就像一个自定义层,它将二维卷积层,批量标准化和ReLU层应用于传递的输入。 当我们有重复的代码结构时,最好创建一个新层,以使代码看起来更优雅。
InceptionBasicBlock实现了我们在第二个Inception图中的内容。 让我们浏览每个较小的片段,并尝试了解它是如何实现的:
branchlxl = self.branchlxl(x)
前面的代码通过应用1 x 1卷积块来转换输入:
branch5x5 = self.branch5x5_l(x)
branch5x5 = self.branch5x5_2(branch5x5)
在前面的代码中,我们通过应用1 x 1卷积块然后使用5 x 5卷积块来转换输入:
branch3x3dbl = self.branch3x3dbl_l(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
在前面的代码中,我们通过应用1 x 1卷积块然后使用3 x 3卷积块来转换输入:
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=l, padding=l)
branch_pool = self.branch_pool(branch_pool)
在前面的代码中,我们应用了一个平均池和一个1 x 1卷积块,最后,我们将所有结果连接在一起。 初始网络将包含多个Inception块。 下图显示了Inception体系结构的外观:
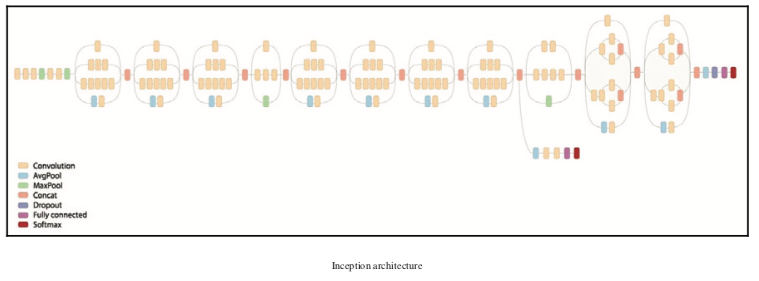
torch.cuda.empty_cache()
torchvision软件包有一个Inception网络,可以像我们使用ResNet网络一样使用。 对初始的Inception块进行了许多改进,PyTorch提供的当前实现是Inception v3。 让我们看一下如何使用torchvision的Inception v3模型来计算预先计算的特征。 我们不会完成数据加载过程,因为我们将使用之前ResNet部分中的相同数据加载器。 我们将看看以下重要主题:
- 创建初始模型
- 使用register_forward_hook提取卷积特征
- 为复杂功能创建新数据集
- 创建完全连接的模型
- 训练和验证模型
创建一个Inception模型
Inception v3模型有两个分支,每个分支都生成一个输出,在原始模型训练中,我们将合并损失,就像我们为样式转移所做的那样。 截至目前,我们感兴趣的是只使用一个分支来使用Inception计算预卷积特征。 详细了解这一点超出了本书的范围。 如果您有兴趣了解它的工作原理,那么请阅读论文和论文 源代码(https://github.com/pytorch/vision/blob/master/torchvision/models/ inception模型的inception.py)会有所帮助。 我们可以通过将aux_logits参数设置为False来禁用其中一个分支。 以下代码说明了如何创建模型并将aux_logits参数设置为False:
from torchvision.models.inception import inception_v3
my_inception = inception_v3(pretrained=True)
my_inception.aux_logits = False
if is_cuda:
my_inception = my_inception.cuda()
从初始模型中提取卷积特征并不像ResNet那样简单,因此我们将使用register_forward_hook来提取激活。
使用register_forward_hook提取卷积特征
我们将使用与计算样式迁移激活相同的技术。 以下是LayerActivations类,稍作修改,因为我们只想提取特定图层的输出:
class LayerActivations():
features=[]
def __init__(self,model):
self.features = []
self.hook = model.register_forward_hook(self.hook_fn)
def hook_fn(self,module,input,output):
self.features.extend(output.view(output.size(0),-1).cpu().data)
def remove(self):
self.hook.remove()
除了钩子函数之外,其余代码类似于我们用于样式传递的代码。 当我们捕获所有图像的输出并存储它们时,我们将无法将数据保存在图形处理单元(GPU)内存中。 因此我们将张量从GPU提取到CPU,只存储张量而不是变量。 我们正在将其转换回张量,因为数据加载器仅适用于张量。 在下面的代码中,我们使用LayerActivations的对象来提取最后一层的Inception模型的输出,不包括平均池层,dropout和线性层。 我们正在跳过平均池层以避免丢失数据中的有用信息:
# Create LayerActivations object to store the output of inception model at a particular layer.
trn_features = LayerActivations(my_inception.Mixed_7c)
trn_labels = []
# Passing all the data through the model , as a side effect the outputs will get stored
# in the features list of the LayerActivations object.
for da,la in train_loader:
_ = my_inception(Variable(da.cuda()))
trn_labels.extend(la)
trn_features.remove()
# Repeat the same process for validation dataset .
val_features = LayerActivations(my_inception.Mixed_7c)
val_labels = []
for da,la in val_loader:
_ = my_inception(Variable(da.cuda()))
val_labels.extend(la)
val_features.remove()
让我们为所需的新的卷积特征创建数据集和加载器。
为卷积的特征创建新数据集
我们可以使用相同的FeaturesDataset类来创建新的数据集和数据加载器。 在以下代码中,我们创建数据集和加载器:
#Dataset for pre computed features for train and validation data sets
trn_feat_dset = FeaturesDataset(trn_features.features,trn_labels)
val_feat_dset = FeaturesDataset(val_features.features,val_labels)
#Data loaders for pre computed features for train and validation data sets
trn_feat_loader = DataLoader(trn_feat_dset,batch_size=64,shuffle=True)
val_feat_loader = DataLoader(val_feat_dset,batch_size=64)
让我们创建一个新模型来训练预先卷积的特征。
创建完全连接的模型
一个简单的模型可能以过度拟合结束,所以让我们在模型中包含dropout。 Dropout有助于避免过度拟合。 在下面的代码中,我们创建了我们的模型:
class FullyConnectedModel(nn.Module):
def __init__(self,in_size,out_size,training=True):
super().__init__()
self.fc = nn.Linear(in_size,out_size)
def forward(self,inp):
out = F.dropout(inp, training=self.training)
out = self.fc(out)
return out
# The size of the output from the selected convolution feature
fc_in_size = 131072
fc = FullyConnectedModel(fc_in_size,classes)
if is_cuda:
fc = fc.cuda()
创建模型后,我们可以训练模型。
训练和验证模型
我们使用与之前的ResNet和其他示例中相同的拟合和训练逻辑。 我们将只看一下培训代码及其结果:
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,10):
epoch_loss, epoch_accuracy = fit(epoch,fc,trn_feat_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,fc.eval(),val_feat_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
查看结果,Inception模型在训练上达到99%的准确率,在验证数据集上达到97.8%的准确度。 由于我们预先计算并保存内存中的所有功能,因此训练模型所需的时间不到几分钟。 如果在计算机上运行程序时内存不足,则可能需要避免将功能保留在内存中。 我们将看看另一个有趣的架构,DenseNet,它在去年变得非常流行。
密集连接的卷积网络 - DenseNet
一些成功和流行的架构,如ResNet和Inception,已经表明了更深层次和更广泛的网络的重要性。 ResNet使用快捷连接来构建更深入的网络。 DenseNet通过将每个层的连接引入所有其他后续层(即可以从前面的层接收所有特征的层)将其提升到一个新的水平。 基于符号的表示如下:
$X_i = H_i(X_0,X_I,X_2,…,X_{i-1})$
下图描述了五层密集块的外观:
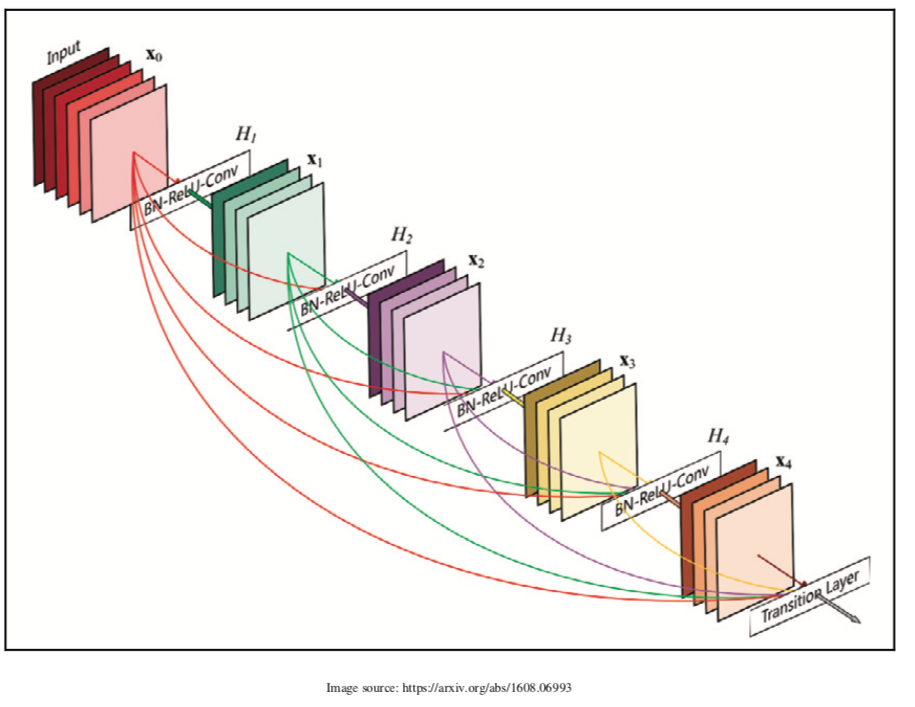
有一个关于torchvision的密集网实现(https://github.com/pytorch/vision/blob/master/torchvision/models/densenet.py)。 让我们看看两个主要功能块,_DenseBlock 和_DenseLayer。
import pandas as pd
from glob import glob
import os
from shutil import copyfile
from torch.utils.data import Dataset
from PIL import Image
import numpy as np
from numpy.random import permutation
import matplotlib.pyplot as plt
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torchvision.models import resnet18,resnet34
from torchvision.models.inception import inception_v3
from torchvision.models import densenet121
from torch.utils.data import DataLoader
from torch.autograd import Variable
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
%matplotlib inline
is_cuda = torch.cuda.is_available()
is_cuda
True
DenseBlock
让我们看一下DenseBlock的代码,然后介绍它:
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('denselayer%d' % (i + 1), layer)
DenseBlock是一个顺序模块,我们按顺序添加图层。 根据块中的层数(num_layers),我们将_Denselayer对象的数量与名称一起添加。 所有的魔法都发生在DenseLayer中。 让我们来看看DenseLayer里面发生了什么。
DenseLayer
了解特定网络如何工作的一个好方法是查看源代码。 PyTorch有一个非常干净的实现,大部分都很容易阅读。 我们来看看DenseLayer的实现:
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size *
growth_rate, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
如果您不熟悉Python中的继承,那么前面的代码可能看起来不直观。 _DenseLayer是nn.Sequential的子类; 让我们来看看每个内部方法发生了什么。
在__init__方法中,我们添加了输入数据需要传递给的所有层。 它与我们看到的所有其他网络架构非常相似。 魔法发生在forward方法中。 我们将输入传递给超类的forward方法,即nn.Sequential。 让我们看一下顺序类的forward方法会发生什么( https://github.com/pytorch/pytorch/blob/409blc8319ecde4bd62fcf98d0a6658ae7a4ab23/torch/nn/modules/container.py ):
def forward(self, input):
for module in self._modules.values():
input = module(input)
return input
输入传递到先前添加到顺序块的所有层,输出连接到输入。 对块中所需数量的层重复该过程。
通过了解DenseNet模块的工作原理,让我们探讨如何使用DenseNet计算预先复杂的特征并在其上构建分类器模型。 在较高的层面上,DenseNet实现类似于VGG实现。 DenseNet实现还具有功能模块和分类器模块,功能模块包含所有密集块,分类器模块包含完全连接的模型。 我们将通过以下步骤来构建模型。 我们将跳过大部分类似于我们在Inception和ResNet中看到的部分,例如创建数据加载器和数据集。 此外,我们将详细讨论以下步骤:
- 创建DenseNet模型
- 提取DenseNet特征
- 创建数据集和加载器
- 创建全连接的模型和训练
到目前为止,大多数代码都是不言自明的。
功能函数
def imshow(inp,cmap=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp,cmap)
class FeaturesDataset(Dataset):
def __init__(self,featlst,labellst):
self.featlst = featlst
self.labellst = labellst
def __getitem__(self,index):
return (self.featlst[index],self.labellst[index])
def __len__(self):
return len(self.labellst)
def fit(epoch,model,data_loader,phase='training',volatile=False):
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , (data,target) in enumerate(data_loader):
if is_cuda:
data,target = data.cuda(),target.cuda()
data , target = Variable(data,volatile),Variable(target)
if phase == 'training':
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output,target)
running_loss += F.cross_entropy(output,target,size_average=False).data[0]
preds = output.data.max(dim=1,keepdim=True)[1]
running_correct += preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy}')
return loss,accuracy
建立 PyTorch 数据集
data_transform = transforms.Compose([
transforms.Resize((299,299)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# For Dogs & Cats dataset
train_dset = ImageFolder('../all/train/',transform=data_transform)
val_dset = ImageFolder('../all/valid/',transform=data_transform)
classes=2
imshow(train_dset[150][0])

创建数据集和加载器
我们将使用我们为ResNet创建的相同FeaturesDataset类,并使用它在以下代码中为训练和验证数据集创建数据加载器:
train_loader = DataLoader(train_dset,batch_size=32,shuffle=False,num_workers=3)
val_loader = DataLoader(val_dset,batch_size=32,shuffle=False,num_workers=3)
创建DenseNet模型
Torchvision具有预训练的DenseNet模型,具有不同的层选项(121,169,201,161)。 我们选择了121层的模型。 如上所述,DenseNet有两个模块:功能(包含密集块)和分类器(完全连接块)。 由于我们使用DenseNet作为图像特征提取器,我们将仅使用特征模块:
my_densenet = densenet121(pretrained=True).features
if is_cuda:
my_densenet = my_densenet.cuda()
for p in my_densenet.parameters():
p.requires_grad = False
/Users/zhipingxu/anaconda3/lib/python3.6/site-packages/torchvision/models/densenet.py:212: UserWarning: nn.init.kaiming_normal is now deprecated in favor of nn.init.kaiming_normal_.
nn.init.kaiming_normal(m.weight.data)
让我们从图像中提取DenseNet特征。
提取DenseNet特征
它与我们为Inception所做的非常相似,只是我们没有使用register_forward_hook来提取特征。 以下代码显示了如何提取DenseNet特征:
#For training data
trn_labels = []
trn_features = []
#code to store densenet features for train dataset.
for d,la in train_loader:
o = my_densenet(Variable(d.cuda()))
o = o.view(o.size(0),-1)
trn_labels.extend(la)
trn_features.extend(o.cpu().data)
#For validation data
val_labels = []
val_features = []
#Code to store densenet features for validation dataset.
for d,la in val_loader:
o = my_densenet(Variable(d.cuda()))
o = o.view(o.size(0),-1)
val_labels.extend(la)
val_features.extend(o.cpu().data)
前面的代码类似于我们在Inception和ResNet中看到的代码。
创建训练和验证特征数据集
# Create dataset for train and validation convolution features
trn_feat_dset = FeaturesDataset(trn_features,trn_labels)
val_feat_dset = FeaturesDataset(val_features,val_labels)
# Create data loaders for batching the train and validation datasets
trn_feat_loader = DataLoader(trn_feat_dset,batch_size=64,shuffle=True,drop_last=True)
val_feat_loader = DataLoader(val_feat_dset,batch_size=64)
创建全连接的模型和训练
我们将使用一个简单的线性模型,类似于我们在ResNet和Inception中使用的模型。 以下代码显示了我们将用于训练模型的网络体系结构:
class FullyConnectedModel(nn.Module):
def __init__(self,in_size,out_size):
super().__init__()
self.fc = nn.Linear(in_size,out_size)
def forward(self,inp):
out = self.fc(inp)
return out
trn_features[0].size(0)
82944
fc_in_size = trn_features[0].size(0)
fc = FullyConnectedModel(fc_in_size,classes)
if is_cuda:
fc = fc.cuda()
optimizer = optim.Adam(fc.parameters(),lr=0.0001)
Train and validate the model
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,10):
epoch_loss, epoch_accuracy = fit(epoch,fc,trn_feat_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,fc,val_feat_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
/Users/zhipingxu/anaconda3/lib/python3.6/site-packages/torch/nn/functional.py:52: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
/Users/zhipingxu/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:39: UserWarning: invalid index of a 0-dim tensor. This will be an error in PyTorch 0.5. Use tensor.item() to convert a 0-dim tensor to a Python number
training loss is 0.059 and training accuracy is 22497/2300097
validation loss is 0.029 and validation accuracy is 1977/200098
training loss is 0.0056 and training accuracy is 22948/2300099
validation loss is 0.027 and validation accuracy is 1982/200099
training loss is 0.0014 and training accuracy is 22976/2300099
validation loss is 0.021 and validation accuracy is 1988/200099
training loss is 0.00063 and training accuracy is 22976/2300099
validation loss is 0.02 and validation accuracy is 1989/200099
training loss is 0.00043 and training accuracy is 22976/2300099
validation loss is 0.019 and validation accuracy is 1990/200099
training loss is 0.00032 and training accuracy is 22976/2300099
validation loss is 0.019 and validation accuracy is 1990/200099
training loss is 0.00025 and training accuracy is 22976/2300099
validation loss is 0.018 and validation accuracy is 1990/200099
training loss is 0.0002 and training accuracy is 22976/2300099
validation loss is 0.018 and validation accuracy is 1991/200099
training loss is 0.00016 and training accuracy is 22976/2300099
validation loss is 0.018 and validation accuracy is 1991/200099
上述算法能够实现99%的最大训练精度和99%的验证准确度。 您创建的验证数据集可能会有不同的图像,您的结果可能会发生变化。 DenseNet的一些优点是:
- 它大大减少了所需参数的数量
- 它缓解了消失的梯度问题
- 它鼓励特征的重用
在下一节中,我们将探讨如何使用ResNet,Inception和DenseNet的不同模型集成到一个模型中,该模型结合了计算出的特征的混合优势。
模型集成
有时候我们需要尝试组合多个模型来构建一个非常强大的模型。 有许多技术可用于构建集成模型。 在本节中,我们将学习如何使用由三个不同模型(ResNet,Inception和DenseNet)生成的特征组合输出,以构建强大的模型。 我们将使用与本章中其他示例相同的数据集。
集成模型的体系结构如下所示:
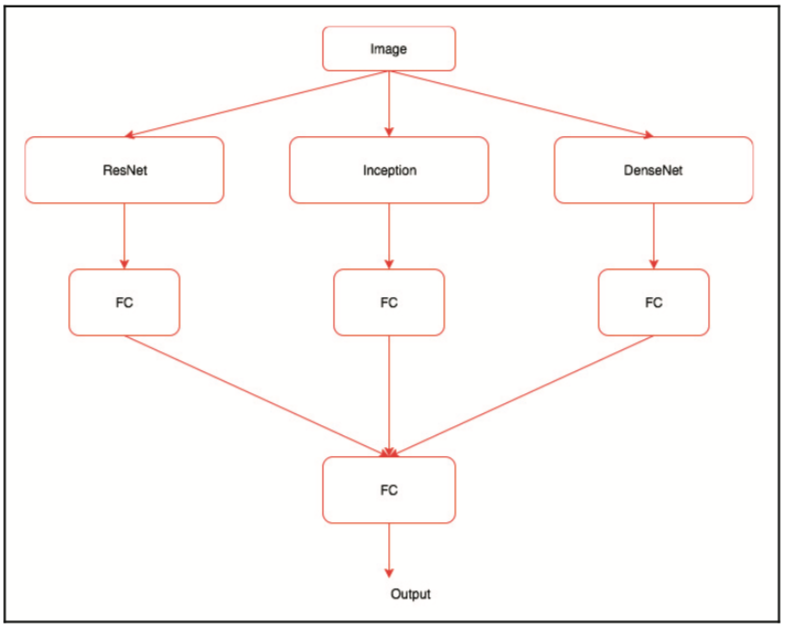
此图显示了我们将在集合模型中执行的操作,可以按以下步骤进行总结:
1.创建三个模型
2.使用创建的模型提取图像特征
3.创建自定义数据集,该数据集返回所有三个模型的特征以及标签
4.创建类似于上图中的体系结构的模型
5.训练并验证模型
让我们详细探讨每个步骤。
创建模型
让我们创建所有三个必需的模型,如下面的代码所示:
#Create ResNet model
my_resnet = resnet34(pretrained=True)
if is_cuda:
my_resnet = my_resnet.cuda()
my_resnet = nn.Sequential(*list(my_resnet.children())[:-1])
for p in my_resnet.parameters():
p.requires_grad = False
#Create inception model
my_inception = inception_v3(pretrained=True)
my_inception.aux_logits = False
if is_cuda:
my_inception = my_inception.cuda()
for p in my_inception.parameters():
p.requires_grad = False
#Create densenet model
my_densenet = densenet121(pretrained=True).features
if is_cuda:
my_densenet = my_densenet.cuda()
for p in my_densenet.parameters():
p.requires_grad = False
现在我们拥有所有模型,让我们从图像中提取特征。
提取图像特征
在这里,我们将本章所见的所有逻辑组合在本章的算法中:
### For ResNet
trn_labels = []
trn_resnet_features = []
for d,la in train_loader:
o = my_resnet(Variable(d.cuda()))
o = o.view(o.size(0),-1)
trn_labels.extend(la)
trn_resnet_features.extend(o.cpu().data)
val_labels = []
val_resnet_features = []
for d,la in val_loader:
o = my_resnet(Variable(d.cuda()))
o = o.view(o.size(0),-1)
val_labels.extend(la)
val_resnet_features.extend(o.cpu().data)
### For Inception
trn_inception_features = LayerActivations(my_inception.Mixed_7c)
for da,la in train_loader:
_ = my_inception(Variable(da.cuda()))
trn_inception_features.remove()
val_inception_features = LayerActivations(my_inception.Mixed_7c)
for da,la in val_loader:
_ = my_inception(Variable(da.cuda()))
val_inception_features.remove()
### For Densenet
trn_densenet_features = []
for d,la in train_loader:
o = my_densenet(Variable(d.cuda()))
o = o.view(o.size(0),-1)
trn_densenet_features.extend(o.cpu().data)
val_densenet_features = []
for d,la in val_loader:
o = my_densenet(Variable(d.cuda()))
o = o.view(o.size(0),-1)
val_densenet_features.extend(o.cpu().data)
到目前为止,我们已经使用所有模型创建了图像功能。 如果您遇到内存问题,则可以删除其中一个模型,或者停止将功能存储在内存中,这可能会很慢。 如果您在CUDA实例上运行它,那么您可以使用更强大的实例。
创建自定义数据集以及数据加载器
我们将无法使用FeaturesDataset类,因为它是为了从一个模型的输出中选择而开发的。 因此,以下实现包含对FeaturesDataset类的微小更改,以适应所有三种不同的生成功能:
class FeaturesDataset(Dataset):
def __init__(self,featlst1,featlst2,featlst3,labellst):
self.featlst1 = featlst1
self.featlst2 = featlst2
self.featlst3 = featlst3
self.labellst = labellst
def __getitem__(self,index):
return (self.featlst1[index],self.featlst2[index],self.featlst3[index],self.labellst[index])
def __len__(self):
return len(self.labellst)
trn_feat_dset = FeaturesDataset(trn_resnet_features,trn_inception_features.features,
trn_densenet_features,trn_labels)
val_feat_dset = FeaturesDataset(val_resnet_features,val_inception_features.features,
val_densenet_features,val_labels)
我们对__init__方法进行了更改,以存储从不同模型生成的所有特征,并使用__getitem__方法来检索图像的特征和标签。 使用FeatureDataset类,我们为训练和验证数据创建了数据集实例。 创建数据集后,我们可以使用相同的数据加载器来批处理数据,如以下代码所示:
trn_feat_loader = DataLoader(trn_feat_dset,batch_size=64,shuffle=True)
val_feat_loader = DataLoader(val_feat_dset,batch_size=64)
创建一个集成模型
我们需要创建一个类似于之前显示的架构图的模型。 以下代码实现了这个:
class EnsembleModel(nn.Module):
def __init__(self,out_size,training=True):
super().__init__()
self.fc1 = nn.Linear(8192,512)
self.fc2 = nn.Linear(131072,512)
self.fc3 = nn.Linear(82944,512)
self.fc4 = nn.Linear(512,out_size)
def forward(self,inp1,inp2,inp3):
out1 = self.fc1(F.dropout(inp1,training=self.training))
out2 = self.fc2(F.dropout(inp2,training=self.training))
out3 = self.fc3(F.dropout(inp3,training=self.training))
out = out1 + out2 + out3
out = self.fc4(F.dropout(out,training=self.training))
return out
em = EnsembleModel(2)
if is_cuda:
em = em.cuda()
optimizer = optim.Adam(em.parameters(),lr=0.01)
在前面的代码中,我们创建了三个线性层,它们采用从不同模型生成的特征。 我们总结了这三个线性层的所有输出,并将它们传递给另一个线性层,将其映射到所需的类别。 为了防止模型过度拟合,我们使用了dropout。
训练和验证模型
我们需要对fit方法进行一些小的更改,以适应从数据加载器生成的三个输入值。 以下代码实现了新的fit函数:
def fit(epoch,model,data_loader,phase='training',volatile=False):
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , (data1,data2,data3,target) in enumerate(data_loader):
if is_cuda:
data1,data2,data3,target = data1.cuda(),data2.cuda(),data3.cuda(),target.cuda()
data1,data2,data3,target = Variable(data1,volatile),Variable(data2,volatile),Variable(data3,volatile),Variable(target)
if phase == 'training':
optimizer.zero_grad()
output = model(data1,data2,data3)
loss = F.cross_entropy(output,target)
running_loss += F.cross_entropy(output,target,size_average=False).data[0]
preds = output.data.max(dim=1,keepdim=True)[1]
running_correct += preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{10}.{4}}')
return loss,accuracy
从前面的代码可以看出,除了加载器返回三个输入和一个标签之外,大多数都保持不变。 因此,我们对函数进行了更改,这是不言自明的。
以下代码显示了训练代码:
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,10):
epoch_loss, epoch_accuracy = fit(epoch,em,trn_feat_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,em,val_feat_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
整体模型的训练精度达到99.6%,验证准确率达到99.3%。 尽管集成模型功能强大,但它们的计算成本却很高。 当你在Kaggle等比赛中解决问题时,它们是很好的技巧。
编码器 - 解码器架构
我们在本书中看到的几乎所有深度学习算法都擅长学习如何将训练数据映射到相应的标签。 我们不能将它们直接用于模型需要从序列中学习并生成另一个序列或图像的任务。 一些示例应用程序是:
- 语言翻译
- 图像字幕
- 图像生成(seq2img)
- 语音识别
- 问题回答
这些问题中的大多数可以被视为某种形式的序列到序列映射,并且这些可以使用称为编码器 - 解码器架构的一系列架构来解决。 在本节中,我们将了解这些体系结构背后的概念。 我们不会考虑这些网络的实施,因为需要对它们进行更详细的研究。
在较高的层次上,编码器 - 解码器架构如下所示:
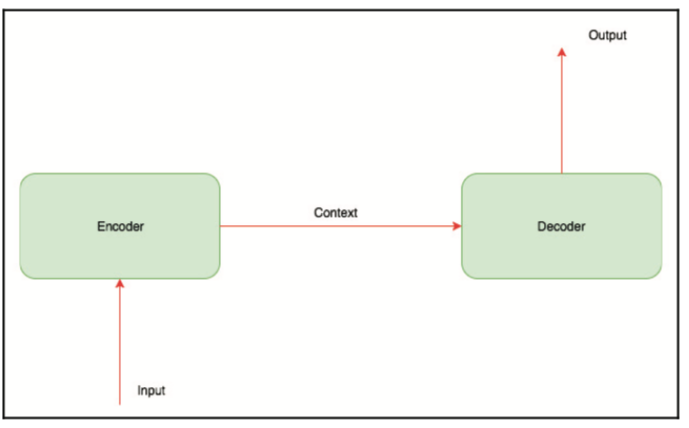
编码器通常是递归神经网络(RNN)(用于顺序数据)或卷积神经网络(CNN)(用于图像),其接收图像或序列并将其转换为编码所有信息的固定长度矢量。 解码器是另一个RNN或CNN,其学习解码由编码器生成的矢量并生成新的数据序列。 下图显示了编码器 - 解码器架构如何进行图像自动标签系统的实现:

让我们更详细地了解编码器内部发生的情况以及图像标题系统的解码器架构。
编码器
对于图像标题系统,我们将优选地使用训练的体系结构(例如ResNet或Inception)来从图像中提取特征。就像我们对集合模型所做的那样,我们可以通过使用线性层输出固定的矢量长度,然后使该线性层可训练。
解码器
解码器是长短期记忆(LSTM)层,它将为图像生成标题。要构建一个简单的模型,我们只需将编码器嵌入作为输入传递给LSTM一次。但是解码器学习起来可能非常具有挑战性;相反,通常的做法是在解码器的每个步骤提供编码器嵌入。直观地,解码器学习生成最能描述给定图像的标题的文本序列。
小结
在本章中,我们探讨了一些现代架构,例如ResNet,Inception和DenseNet。我们还探讨了如何将这些模型用于传输学习和集成,并介绍了编码器 - 解码器架构,它为许多系统提供了动力,例如语言翻译系统。 在下一章中,我们将通过本书得出我们在学习过程中所取得的成果,并讨论从哪里可以走到这里。我们将访问PyTorch上的大量资源以及使用PyTorch创建或正在进行研究的一些很酷的深度学习项目。