基于MNIST数据集进行训练
您已经学习了Chainer和MNIST数据集的基础知识。现在我们可以继续进行MNIST分类任务。我们想要创建一个分类器,将MNIST手写图像分类到其对应的数字中。换句话说,分类器将得到表示MNIST图像的数组作为输入并输出其标签。
Chainer包含称为Trainer,Iterator,Updater的模块,使您的训练代码更有条理。用更高级的语法编写你的训练代码是相当不错的。然而,它的抽象使得很难理解培训期间发生的事情。对于那些想更深入地学习深度学习的人来说,我认为很好的了解编写训练代码的“原始方式”。因此,我故意先不要用这些模块来解释训练码。
定义网络和损失函数
我们采用最简单的神经网络–多层感知器(MLP)作为我们的模型。用Chainer写成如下,
# Initial setup following http://docs.chainer.org/en/stable/tutorial/basic.html
import numpy as np
import chainer
from chainer import cuda, Function, gradient_check, report, training, utils, Variable
from chainer import datasets, iterators, optimizers, serializers
from chainer import Link, Chain, ChainList
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
%matplotlib inline
class MLP(chainer.Chain):
"""Neural Network definition, Multi Layer Perceptron"""
def __init__(self, n_units, n_out):
super(MLP, self).__init__()
with self.init_scope():
# the size of the inputs to each layer will be inferred when `None`
self.l1 = L.Linear(None, n_units) # n_in -> n_units
self.l2 = L.Linear(None, n_units) # n_units -> n_units
self.l3 = L.Linear(None, n_out) # n_units -> n_out
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = self.l3(h2)
return y
这个模型的图形绘制如下。所有节点都是完全连通的,具有这种结构的网络称为MLP(多层感知器)。
第一部分是输入层,最后部分是输出层。其余的中间部分被称为“隐藏层”。这个例子只包含1个隐藏层,但隐藏层可能存在多于1个(如果构建网络更深,隐藏层数会增加)。
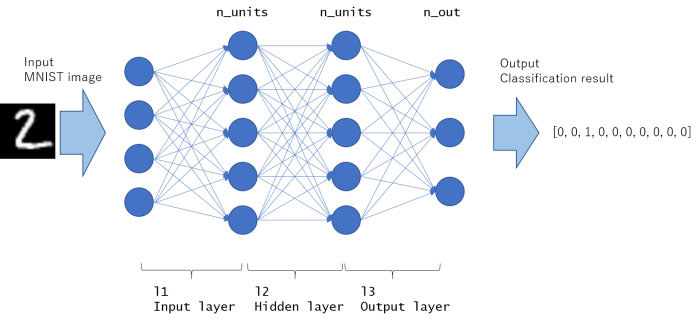
如__call__函数中所写的,它将以x(数组指示图像)作为输入并返回y(指示每个标签的预测概率)作为输出。
但是,这对于训练模型是不够的。我们需要损失函数进行优化。在分类任务中,经常使用softmax交叉熵损失。
全连接层的输出可以采用任意实数,Softmax函数将其转换为0-1之间,因此可以将其视为“该标签的概率”。交叉熵是计算两个概率分布之间的损失。 Chainer具有函数F.softmax_cross_entropy(y,t)来计算y和t的softmax 交叉熵。如果预测为y的概率分布等于实际概率分布t,则损失将更小。直观地说,当模型可以预测给定图像正确的标签时,损失减少。
为了计算softmax交叉熵损失,我们定义如下的另一个Chain类,名为SoftmaxClassifier,
class SoftmaxClassifier(chainer.Chain):
def __init__(self, predictor):
super(SoftmaxClassifier, self).__init__(
predictor=predictor
)
def __call__(self, x, t):
y = self.predictor(x)
self.loss = F.softmax_cross_entropy(y, t)
self.accuracy = F.accuracy(y, t)
return self.loss
然后,模型被实例化为
unit = 50 # Number of hidden layer units, try incresing this value and see if how accuracy changes.
# Set up a neural network to train
model = MLP(unit, 10)
# Classifier will calculate classification loss, based on the output of model
classifier_model = SoftmaxClassifier(model)
首先,MLP模型被创建。 n_out被设定为10,因为MNIST在标签中有10个模式,从0到9。然后根据MLP模型作为预测器创建classifier_model。正如你在这里看到的,Chain类的网络可以被“连接”来构建也是Chain类的新网络。我想这就是Chainer这个名字的由来。
一旦在模型的__call__函数中定义了损失函数计算,您可以将此模型设置为优化器以进行训练
# Setup an optimizer
optimizer = chainer.optimizers.Adam()
optimizer.setup(classifier_model)
然后调用如下命令
# Pass the loss function (Classifier defines it) and its arguments
optimizer.update(classifier_model, x, t)
这段代码将使用Optimizer的算法(本例中为Adam)将损失计算为classifier_model(x,t)并调整(优化)模型的内部参数。
请注意,反向传播是在这个更新代码中自动完成的,所以你不需要明确地写这些代码。
如下所示,我们将在minibatch单元中传递x和t。
使用 GPU
Chainer支持GPU加速计算。要使用GPU,PC必须具有NVIDIA GPU,并且需要安装CUDA,并且最好安装cudnn,然后安装chainer。
要编写GPU兼容的代码,只需添加这4行。
if gpu >= 0:
chainer.cuda.get_device(gpu).use() # Make a specified GPU current
classifier_model.to_gpu() # Copy the model to the GPU
xp = np if gpu < 0 else cuda.cupy
您需要在变量gpu中设置gpu设备ID。
如果不使用GPU,请设置gpu = -1,表示不使用GPU,只使用CPU。在这种情况下,numpy(在上面写成np)用于数组计算。
如果你想使用GPU,设置GPU = 0等(一般消费电脑与NVIDIA GPU包含一个GPU核心,因此只有GPU设备ID = 0可以使用。GPU集群有几个GPU(0,1,2,3等)在一台PC)。在这种情况下,调用chainer.cuda.get_device(gpu).use()来指定要使用的GPU设备,并使用model.to_gpu()将模型的内部参数复制到GPU中。在这种情况下,cupy用于数组计算。
cupy
在Python科学计算中,numpy广泛用于向量,矩阵和一般张量计算。 numpy会自动优化这些与CPU的线性运算。 cupy可以被认为是numpy的GPU版本,这样你就可以写出与numpy几乎相同的GPU计算代码。由Chainer团队开发,作为在Chainer版本1中的chainer.cuda.cupy。 但是,cupy本身可以用作numpy的GPU版本,因此适用于更广泛的用例,不仅适用于chainer。所以cupy将从chainer中独立出来,并作为chainer版本2中的cupy模块提供。
训练和评估(测试)
代码由2阶段,训练阶段和评估(测试)阶段组成。
在机器学习的回归/分类任务中,您需要验证模型的泛化性能。即使损失正在随着训练数据集的减少而减少,测试(看不到的)数据集的损失也不总是如此减少。这里,尤其要注意过拟合问题。
训练阶段
optimizer.update代码将更新模型的内部参数以降低损失。随机排列是随机抽样构造小批量。如果训练损失从一开始就不减少,根本原因可能是模型是错误的,或者一些超参数设置是错误的。当训练失败停止减少(饱和)时,可以停止训练。
# training
perm = np.random.permutation(N)
sum_accuracy = 0
sum_loss = 0
start = time.time()
for i in six.moves.range(0, N, batchsize):
x = chainer.Variable(xp.asarray(train[perm[i:i + batchsize]][0]))
t = chainer.Variable(xp.asarray(train[perm[i:i + batchsize]][1]))
# Pass the loss function (Classifier defines it) and its arguments
optimizer.update(classifier_model, x, t)
sum_loss += float(classifier_model.loss.data) * len(t.data)
sum_accuracy += float(classifier_model.accuracy.data) * len(t.data)
end = time.time()
elapsed_time = end - start
throughput = N / elapsed_time
print('train mean loss={}, accuracy={}, throughput={} images/sec'.format(
sum_loss / N, sum_accuracy / N, throughput))
评估(测试)阶段
我们不能调用optimizer.update代码。测试数据集被认为是模型的不可见数据。不应该被包含作为训练信息。
我们不需要在测试阶段进行随机排列,只需要sum_loss和sum_accuracy。
评估代码确实(应该)对模型没有影响。这只是为了检查测试数据集的损失。理想模式当然是通过训练减少测试损失。
# evaluation
sum_accuracy = 0
sum_loss = 0
for i in six.moves.range(0, N_test, batchsize):
index = np.asarray(list(range(i, i + batchsize)))
x = chainer.Variable(xp.asarray(test[index][0]))
t = chainer.Variable(xp.asarray(test[index][1]))
loss = classifier_model(x, t)
sum_loss += float(loss.data) * len(t.data)
sum_accuracy += float(classifier_model.accuracy.data) * len(t.data)
print('test mean loss={}, accuracy={}'.format(
sum_loss / N_test, sum_accuracy / N_test))
如果这种测试损失不减少,而训练损失正在减少,则表明模型过度拟合。那么,你需要采取行动
- 增加数据大小(如果可能的话)。
- 数据增强是有效增加数据的一种方法。
- 减少神经网络中的内部参数数量
- 尝试更简单的网络
- 添加正则化术项目
把所有的代码放在一起
"""
Very simple implementation for MNIST training code with Chainer using
Multi Layer Perceptron (MLP) model
This code is to explain the basic of training procedure.
"""
from __future__ import print_function
import time
import os
import numpy as np
import six
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import cuda
from chainer import serializers
class MLP(chainer.Chain):
"""Neural Network definition, Multi Layer Perceptron"""
def __init__(self, n_units, n_out):
super(MLP, self).__init__(
# the size of the inputs to each layer will be inferred
l1=L.Linear(None, n_units), # n_in -> n_units
l2=L.Linear(None, n_units), # n_units -> n_units
l3=L.Linear(None, n_out), # n_units -> n_out
)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = self.l3(h2)
return y
class SoftmaxClassifier(chainer.Chain):
"""Classifier is for calculating loss, from predictor's output.
predictor is a model that predicts the probability of each label.
"""
def __init__(self, predictor):
super(SoftmaxClassifier, self).__init__(
predictor=predictor
)
def __call__(self, x, t):
y = self.predictor(x)
self.loss = F.softmax_cross_entropy(y, t)
self.accuracy = F.accuracy(y, t)
return self.loss
def main():
# Configuration setting
gpu = -1 # GPU ID to be used for calculation. -1 indicates to use only CPU.
batchsize = 100 # Minibatch size for training
epoch = 20 # Number of training epoch
out = 'result/1_minimum' # Directory to save the results
unit = 50 # Number of hidden layer units, try incresing this value and see if how accuracy changes.
print('GPU: {}'.format(gpu))
print('# unit: {}'.format(unit))
print('# Minibatch-size: {}'.format(batchsize))
print('# epoch: {}'.format(epoch))
print('out directory: {}'.format(out))
# Set up a neural network to train
model = MLP(unit, 10)
# Classifier will calculate classification loss, based on the output of model
classifier_model = SoftmaxClassifier(model)
if gpu >= 0:
chainer.cuda.get_device(gpu).use() # Make a specified GPU current
classifier_model.to_gpu() # Copy the model to the GPU
xp = np if gpu < 0 else cuda.cupy
# Setup an optimizer
optimizer = chainer.optimizers.Adam()
optimizer.setup(classifier_model)
# Load the MNIST dataset
train, test = chainer.datasets.get_mnist()
n_epoch = epoch
N = len(train) # training data size
N_test = len(test) # test data size
# Learning loop
for epoch in range(1, n_epoch + 1):
print('epoch', epoch)
# training
perm = np.random.permutation(N)
sum_accuracy = 0
sum_loss = 0
start = time.time()
for i in six.moves.range(0, N, batchsize):
x = chainer.Variable(xp.asarray(train[perm[i:i + batchsize]][0]))
t = chainer.Variable(xp.asarray(train[perm[i:i + batchsize]][1]))
# Pass the loss function (Classifier defines it) and its arguments
optimizer.update(classifier_model, x, t)
sum_loss += float(classifier_model.loss.data) * len(t.data)
sum_accuracy += float(classifier_model.accuracy.data) * len(t.data)
end = time.time()
elapsed_time = end - start
throughput = N / elapsed_time
print('train mean loss={}, accuracy={}, throughput={} images/sec'.format(
sum_loss / N, sum_accuracy / N, throughput))
# evaluation
sum_accuracy = 0
sum_loss = 0
for i in six.moves.range(0, N_test, batchsize):
index = np.asarray(list(range(i, i + batchsize)))
x = chainer.Variable(xp.asarray(test[index][0]))
t = chainer.Variable(xp.asarray(test[index][1]))
loss = classifier_model(x, t)
sum_loss += float(loss.data) * len(t.data)
sum_accuracy += float(classifier_model.accuracy.data) * len(t.data)
print('test mean loss={}, accuracy={}'.format(
sum_loss / N_test, sum_accuracy / N_test))
# Save the model and the optimizer
if not os.path.exists(out):
os.makedirs(out)
print('save the model')
serializers.save_npz('{}/classifier_mlp.model'.format(out), classifier_model)
serializers.save_npz('{}/mlp.model'.format(out), model)
print('save the optimizer')
serializers.save_npz('{}/mlp.state'.format(out), optimizer)
if __name__ == '__main__':
main()