Chainer 入门教程(2)
让我们尝试在本教程中训练 Chain 模型。在这一节中,我们将学习
- Optimizer - 优化/调整内部参数以适应目标函数
- Serializer - 处理保存/加载 Chain 模型
其他chainer模块在后面的教程中解释。
训练
我们在这里要做的是回归分析。给定一组输入x和它的输出y,我们想构建一个模型(函数),它估计的y尽可能接近原先给定的输入x的输出y。这是通过调整模型的内部参数来完成的(这是由Chainer中的Chain类表示的)。调整模型的内部参数以获得期望的模型的过程通常被表示为“训练”。
初始设定
下面是chainer模块的导入语句。
# Initial setup following http://docs.chainer.org/en/stable/tutorial/basic.html
import numpy as np
import chainer
from chainer import cuda, Function, gradient_check, report, training, utils, Variable
from chainer import datasets, iterators, optimizers, serializers
from chainer import Link, Chain, ChainList
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
%matplotlib inline
import matplotlib.pyplot as plt
# define target function
def target_func(x):
"""Target function to be predicted"""
return x ** 3 - x ** 2 + x - 3
# create efficient function to calculate target_func of numpy array in element wise
target_func_elementwise = np.frompyfunc(target_func, 1, 1)
# define data domain [xmin, xmax]
xmin = -3
xmax = 3
# number of training data
sample_num = 20
x_data = np.array(np.random.rand(sample_num) * (xmax - xmin) + xmin) # create 20
y_data = target_func_elementwise(x_data)
x_detail_data = np.array(np.arange(xmin, xmax, 0.1))
y_detail_data = target_func_elementwise(x_detail_data)
# plot training data
plt.clf()
plt.scatter(x_data, y_data, color='r')
plt.show()
#print('x', x_data, 'y', y_data)
# plot target function
plt.clf()
plt.plot(x_detail_data, y_detail_data)
plt.show()
优化器
Chainer优化器管理模型拟合的优化过程。 具体而言,目前深度学习基于Stocastic Gradient Descent(SGD)方法的技术。 Chainer在chainer.optimizers模块中提供了几个优化器,其中包括以下内容
- MomentumSGD
- AdaGrad
- AdaDelta
- Adam
就目前而言 MomentumSGD 和 Adam 用的比较多。
构建模型 - 实现自己的Chain
我们来看一个例子,
from chainer import Chain, Variable
# Defining your own neural networks using `Chain` class
class MyChain(Chain):
def __init__(self):
super(MyChain, self).__init__(
l1=L.Linear(None, 30),
l2=L.Linear(None, 30),
l3=L.Linear(None, 1)
)
def __call__(self, x):
h = self.l1(x)
h = self.l2(F.sigmoid(h))
return self.l3(F.sigmoid(h))
这里L.Linear在第一个参数的输入大小中定义为None。当使用None时,全连接将在第一次获取输入变量时确定其输入大小。换句话说,Link的输入大小可以动态地定义,并且您不需要在声明的时候修改大小。这种灵活性来自Chainer的“边运行边定义”的概念。
# Setup a model
model = MyChain()
# Setup an optimizer
optimizer = chainer.optimizers.MomentumSGD()
optimizer.use_cleargrads() # this is for performance efficiency
optimizer.setup(model)
x = Variable(x_data.reshape(-1, 1).astype(np.float32))
y = Variable(y_data.reshape(-1, 1).astype(np.float32))
def lossfun(x, y):
loss = F.mean_squared_error(model(x), y)
return loss
# this iteration is "training", to fit the model into desired function.
for i in range(300):
optimizer.update(lossfun, x, y)
# above one code can be replaced by below 4 codes.
# model.cleargrads()
# loss = lossfun(x, y)
# loss.backward()
# optimizer.update()
y_predict_data = model(x_detail_data.reshape(-1, 1).astype(np.float32)).data
plt.clf()
plt.scatter(x_data, y_data, color='r')
plt.plot(x_detail_data, np.squeeze(y_predict_data, axis=1))
plt.show()
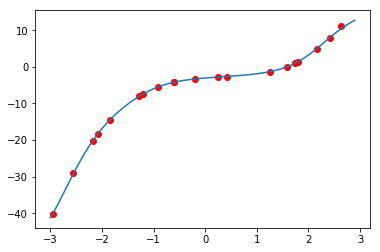
数据形状的注意事项:在创建变量时x_data和y_data的形状被改变。线性函数输入和输出形式为(batch_index,feature_index)。在这个例子中,x_data和y_data具有batch_size = sample_num(20)的一维特征。
首先,优化器被设置为以下代码。我们可以选择在训练期间使用哪种优化方法(在这种情况下,使用MomentumSGD)
一旦优化器被设置,训练继续迭代下面的代码。
optimizer.update(lossfun, x, y)
通过更新,优化器尝试通过减少lossfun定义的损失来调整模型的内部参数。在这个例子中,平方误差被用作损失
def lossfun(x, y):
loss = F.mean_squared_error(model(x), y)
return loss
序列化器
序列化器支持Chainer类的保存/加载。
训练结束后,我们要保存模型,以便我们可以将其加载到推理阶段。另一个用例是我们想要将优化器与模型一起保存,以便我们可以中止并重新开始训练。下面的代码与上面的培训代码几乎相同。只有不同的是serializers.load_npz()(或serializers.load_hdf5())和serializers.save_npz()(或serializers.save_hdf5())被加入,所以现在它支持恢复训练,通过执行保存/加载。
请注意,模型和优化器需要在加载之前实例化为适当的类。
# 在第一次执行时设定 resume = False
# 以后将 resume = True ,不断执行本代码块,看看会有什么结果?
resume = True
# Setup a model
model = MyChain()
# Setup an optimizer
optimizer = chainer.optimizers.MomentumSGD()
optimizer.setup(model)
x = Variable(x_data.reshape(-1, 1).astype(np.float32))
y = Variable(y_data.reshape(-1, 1).astype(np.float32))
model_save_path = 'mlp.model'
optimizer_save_path = 'mlp.state'
# Init/Resume
if resume:
print('Loading model & optimizer')
# --- use NPZ format ---
serializers.load_npz(model_save_path, model)
serializers.load_npz(optimizer_save_path, optimizer)
# --- use HDF5 format (need h5py library) ---
#%timeit serializers.load_hdf5(model_save_path, model)
#serializers.load_hdf5(optimizer_save_path, optimizer)
def lossfun(x, y):
loss = F.mean_squared_error(model(x), y)
return loss
# this iteration is "training", to fit the model into desired function.
# Only 20 iteration is not enough to finish training,
# please execute this code several times by setting resume = True
for i in range(20):
optimizer.update(lossfun, x, y)
# above one code can be replaced by below 4 codes.
# model.cleargrads()
# loss = lossfun(x, y)
# loss.backward()
# optimizer.update()
# Save the model and the optimizer
print('saving model & optimizer')
# --- use NPZ format ---
serializers.save_npz(model_save_path, model)
serializers.save_npz(optimizer_save_path, optimizer)
# --- use HDF5 format (need h5py library) ---
#%timeit serializers.save_hdf5(model_save_path, model)
# serializers.save_hdf5(optimizer_save_path, optimizer)
y_predict_data = model(x_detail_data.reshape(-1, 1).astype(np.float32)).data
plt.clf()
plt.scatter(x_data, y_data, color='r', label='training data')
plt.plot(x_detail_data, np.squeeze(y_predict_data, axis=1), label='model')
plt.legend(loc='lower right')
plt.show()
Loading model & optimizer
saving model & optimizer
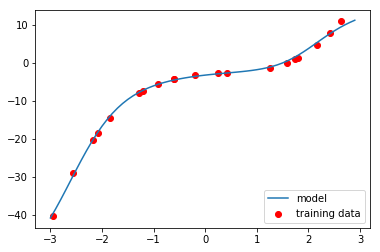
请首先通过设置resume = False来执行上述操作,然后通过设置resume = True来执行上面的代码。
您可以通过训练过程了解模型如何“动态”的适应数据。
预测
一旦模型被训练,您可以将此模型应用于新的数据。 与“训练”相比,这通常被称为“预测”或“推论”
# Setup a model
model = MyChain()
model_save_path = 'mlp.model'
print('Loading model')
# --- use NPZ format ---
serializers.load_npz(model_save_path, model)
# --- use HDF5 format (need h5py library) ---
#%timeit serializers.load_hdf5(model_save_path, model)
# calculate new data from model (predict value)
x_test_data = np.array(np.random.rand(sample_num) * (xmax - xmin) + xmin) # create 20
x_test = Variable(x_test_data.reshape(-1, 1).astype(np.float32))
y_test_data = model(x_test).data # this is predicted value
# calculate target function (true value)
x_detail_data = np.array(np.arange(xmin, xmax, 0.1))
y_detail_data = target_func_elementwise(x_detail_data)
plt.clf()
# plot model predict data
plt.scatter(x_test_data, y_test_data, color='k', label='Model predict value')
# plot target function
plt.plot(x_detail_data, y_detail_data, label='True value')
plt.legend(loc='lower right')
plt.show()
Loading model
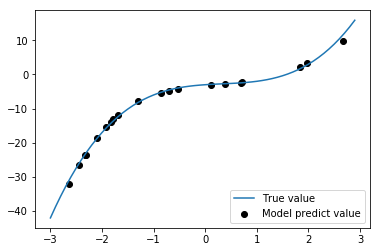
我们将黑点和蓝线比较,黑点最好尽可能靠近蓝线。如果用足够的迭代训练模型,在这个简单的例子中,黑点应该几乎显示在蓝线上。
小结
您了解了优化程序和序列化程序模块,以及如何在训练代码中使用这些模块。优化器更新模型(Chain实例)以适应数据。序列化器提供保存/加载功能给chainer模块,尤其是模型和优化器。
现在你明白了Chainer的基本模块。那么让我们继续以MNIST为例,这在机器学习社区被认为是“hello world”程序。