创建您自己的训练器扩展
在本节中,您将了解以下内容:
- 什么是训练器扩展?
-
如何创建自己的训练器扩展
- 通过定义一个简单的函数
- 通过定义一个用@make_extension装饰的函数
- 通过定义从Extension类继承的类
什么是训练器扩展?
Extension 将 Trainer 对象作为参数的可调用对象。使用 extend() 方法将扩展添加到训练器,将在您使用触发器对象指定的给定时间调用Extension(请参阅1.触发器中的详细信息)。
训练器对象具有训练循环中使用的所有信息,例如模型,优化器,更新器,迭代器和数据集等。因此,您可以更改优化器的设置
import numpy as np
import chainer
from chainer import cuda, Function, gradient_check, report, training, utils, Variable
from chainer import datasets, iterators, optimizers, serializers
from chainer import Link, Chain, ChainList
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
写一个简单的函数
你可以通过编写一个以Trainer对象为参数的简单函数来创建一个新的扩展。例如,如果想在训练期间的特定时间降低学习率,可以将lr_drop扩展写为:
def lr_drop(trainer):
trainer.updater.get_optimizer('main').lr *= 0.1
然后你可以通过extend()方法将这个函数添加到Trainer对象中。
trainer.extend(lr_drop, trigger=(10, 'epoch'))
它通过将当前学习速率乘以0.1来降低每10个epoch的学习速率。
编写一个用@make_extension装饰的函数
make_extension()是一个修饰器,它为给定的函数添加了一些属性。例如,我们上面创建的简单的扩展可以写成这样的形式:
@training.make_extension(trigger=(10, 'epoch'))
def lr_drop(trainer):
trainer.updater.get_optimizer('main').lr *= 0.1
上面这个和这个之间的区别在于它是否有默认的触发器。在后一种情况下,lr_drop()具有其默认触发器,所以除非通过extend()方法指定另一个触发器,否则使用在make_extension()中指定的触发器作为默认值。所以下面的代码与前面的例子的作用相同,即它每10个epoch降低学习速率。
trainer.extend(lr_drop)
有几个属性可以使用make_extension()修饰器添加。
1. trigger
trigger 是一个以 Trainer 对象作为输入参数并且返回布尔值的对象。 如果一个元组 (period, unit) 被给定为一个trigger, 它将被视作在每个周期单元被激发的 IntervalTrigger 。 例如,一个给定的元组是 (10, 'epoch'), 这个扩展将在每 10 个 epoch 被激发。
trigger也可以被赋予extension()方法,该方法将扩展添加到Trainer对象。 trigger的优先级如下:
- 当
extend()和给定的Extension都有触发器时,使用含有extend()的触发器。 - 当
None被指定为extend()作为触发器参数并且给定的Extension具有trigger时,使用含有Extension的trigger。 - 当
extend()和Extension中的trigger属性都是None时,每次迭代都会触发Extension。
请参阅get_trigger()的文档中的详细信息。
2. default_name
Extension保存在Trainer的属性字典中。这个参数给出了扩展名。用户将在由序列化生成的字典的快照的键中看到该名称。
3. priority
priority 用于确定Trainer对象中的扩展执行顺序。有三个标准值的优先级:
- PRIORITY_WRITER: 为观察字典写入一些记录的扩展的优先级。它包括扩展直接为观察词典添加值的情况,或者扩展使用
chainer.report()函数将值报告给观察词典。向报告器写内容的扩展应该先执行,因为可以添加读取这些值的其他扩展。 - PRIORITY_EDITOR: 根据已经报告的值编辑观察词典的扩展优先级。编辑报告数值的扩展的优先级应该排在读最终数值的扩展之前以及其他扩展写入值之后。
- PRIORITY_READER: 只能从观察字典中读取记录的扩展的优先级。这也适用于根本不使用观察字典的扩展。读取报告值的扩展应在所有具有其他优先级的扩展之后触发,例如PRIORITY_WRITER和PRIORITY_EDITOR,因为它应该读取最终值。
请参阅训练器文档中的详细信息。
4. finalizer
你可以指定一个函数,使用Trainer对象来完成扩展。在整个训练循环结束时调用一次,即run()结束。
5. initializer
您可以指定一个函数,它使用Trainer对象来初始化扩展。它在训练循环开始时被调用一次,即在开始实际循环之前。
编写一个从Extension类继承的类
这是以最大的自由度来定义你自己的扩展的方法。您可以将任何值保留在扩展中并将其序列化。
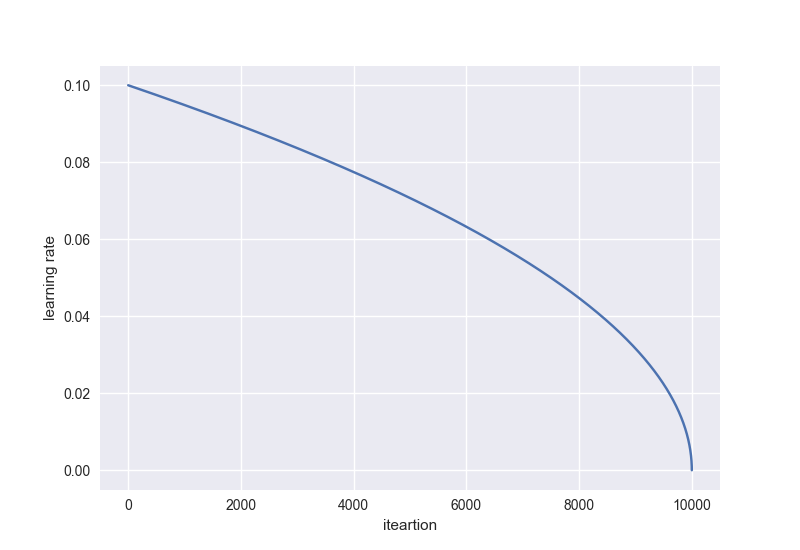
作为一个例子,让我们做一个扩展,降低多项式的学习速度。它通过以下等式计算学习率:
$\eta = \eta_{\rm init} \left( 1 - \frac{t}{t_{\rm max}} \right)^{\rm power}$
学习率将像下面的曲线一样下降 ${\rm power} = 0.5$:
class PolynomialShift(training.Extension):
def __init__(self, attr, power, stop_trigger, batchsize=None,
len_dataset=None):
self._attr = attr
self._power = power
self._init = None
self._t = 0
self._last_value = 0
if stop_trigger[1] == 'iteration':
self._maxiter = stop_trigger[0]
elif stop_trigger[1] == 'epoch':
if batchsize is None or len_dataset is None:
raise ValueError(
'When the unit of \'stop_trigger\' is \'epoch\', '
'\'batchsize\' and \'len_dataset\' should be '
'specified to calculate the maximum iteration.')
n_iter_per_epoch = len_dataset / float(batchsize)
self._maxiter = float(stop_trigger[0] * n_iter_per_epoch)
def initialize(self, trainer):
optimizer = trainer.updater.get_optimizer('main')
# ensure that _init is set
if self._init is None:
self._init = getattr(optimizer, self._attr)
def __call__(self, trainer):
self._t += 1
optimizer = trainer.updater.get_optimizer('main')
value = self._init * ((1 - (self._t / self._maxiter)) ** self._power)
setattr(optimizer, self._attr, value)
self._last_value = value
def serialize(self, serializer):
self._t = serializer('_t', self._t)
self._last_value = serializer('_last_value', self._last_value)
if isinstance(self._last_value, np.ndarray):
self._last_value = np.asscalar(self._last_value)
stop_trigger = (10000, 'iteration')
trainer.extend(PolynomialShift('lr', 0.5, stop_trigger)
这个PolynomialShift扩展有五个参数。
attr: 您希望通过此扩展更新的优化器属性的名称。power: 上述方程的幂次来计算学习率。stop_trigger: 给Trainer对象的触发器指定何时停止训练循环。batchsize: 训练的小批量数据。The training mini-batchsize.len_dataset: 数据集的长度,即训练数据集中的数据数量。
该扩展使用stop_trigger,batchsize和len_dataset计算将在训练中执行的迭代次数,然后将其作为属性_maxiter存储。这个属性将用于__call __()方法来更新学习速率。 initialize()方法从优化器集合中获得初始学习速率给Trainer对象。 serialize()方法存储或恢复本扩展所具有的属性_t(迭代次数)和_last_value(最新学习速率)。